기술 뉴스 · 2 min read · Oct 10, 2025
머신 러닝 저널에서 ‘Hey Siri’ 개인화에 대해 설명
Apple의 머신 러닝 저널에 새 게시물에서 회사는 “Hey Siri” 음성 활성화 기능 뒤에 있는 개인화가 어떻게 작동하는지 설명하여 잘못된 긍정의 수를 줄이는 방법을 설명합니다. 저널은 “Hey Siri” 감지기와 보다 일반적인 화자 독립적인 “키 구문 감지“ 문제의 일반적인 기술 접근 방식 및 구현 세부 사항을 설명하는 이전 항목으로 돌아가며, 이는 이 최신 논문의 가정된 기초로 시작됩니다. 이 논문은 Apple이 주변에서 “Hey Siri”와 유사하게 들릴 수 있는 구문을 말하는 다른 사람들로 인해 발생하는 잘못된 긍정의 수를 줄이기 위해 개발한 기본적인 화자 인식 시스템을 개발하는 데 구현한 머신 러닝 기술에 초점을 맞추고 있습니다.
Apple은 2014년 iPhone 6의 출시와 함께 “Hey Siri”를 도입했으며, 이 기능은 원래 iPhone이 전원에 연결되어 있어야 했습니다. 그러나 1년 후 iPhone 6s의 출시와 함께 새로운 저전력 보조 프로세서 덕분에 “항상 켜져 있는 Hey Siri”가 가능해졌습니다. 이 보조 프로세서는 상당한 배터리 소모 없이 지속적인 청취를 제공할 수 있었습니다. 동시에 이 기능은 iOS 9에서 새로운 “훈련 모드”를 추가하여 초기 설정 중 특정 iPhone 사용자의 음성에 맞게 Siri를 개인화하는 데 도움을 주어 더욱 개선되었습니다.
논문은 “Hey Siri”라는 구문이 가능한 한 자연스럽게 선택되었다고 설명하며, 기능이 도입되기 전에도 Apple은 많은 사용자가 홈 버튼을 사용하여 Siri를 활성화한 후 자연스럽게 “Hey Siri”로 요청을 시작하고 있음을 발견했습니다. 그러나 이 구문의 “간결함과 발음의 용이성”은 양날의 검으로, 더 많은 잘못된 긍정을 초래할 가능성도 있습니다. Apple은 초기 실험에서 의도하지 않은 활성화가 “합리적인 비율”의 올바른 호출에 비해 용납할 수 없을 정도로 높은 수치를 보였다고 설명합니다.
따라서 Apple의 목표는 머신 러닝 기술을 활용하여 “잘못된 수용”의 수를 줄여 Siri가 주 사용자가 “Hey Siri”라고 말할 때만 깨어나도록 하고, 특히 방 안의 제3자가 Siri를 호출하는 것으로 잘못 해석되는 상황을 피하는 것입니다.
Apple은 화자 인식 기술의 “전반적인 목표”가 목소리로 사람의 신원을 결정하는 것이라고 덧붙이며, 이는 Apple의 HomePod와 같은 다중 사용자 장치를 고려할 때 추가적인 개인화 및 인증을 제공할 수 있는 장기 계획을 제안합니다. 목표는 단순히 무엇이 말해지고 있는지를 아는 것이 아니라 “누가 말하고 있는지“를 결정하는 것이며, 논문은 “Hey Siri”와 같은 알려진 구문에 기반한 식별이 이루어지는 “텍스트 의존 화자 인식”과 사용자가 무엇을 말하고 있는지에 관계없이 식별하는 더 도전적인 작업인 “텍스트 독립 화자 인식”의 차이를 설명합니다.
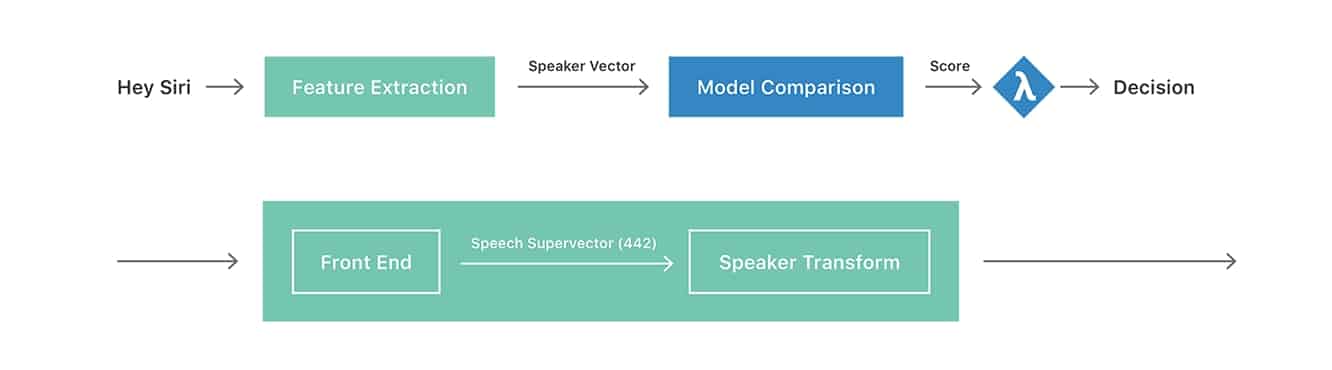
아마도 가장 흥미로운 점은 저널이 Siri가 명시적인 등록 과정(초기 설정 중 사용자가 다섯 가지 다른 “Hey Siri” 구문을 말하도록 요청하는 과정)이 완료된 후에도 사용자의 목소리를 식별하기 위해 “암묵적으로” 계속 훈련하고 있다는 점을 설명합니다. 암묵적 과정은 초기 설정 후 추가적인 “Hey Siri” 요청을 분석하고 이를 사용자 프로필에 추가하여 총 40개의 샘플(“화자 벡터”라고 함)이 저장될 때까지 Siri를 계속 훈련합니다. 여기에는 명시적 훈련 과정에서의 원래 다섯 개가 포함됩니다.
이 화자 벡터의 모음은 이후의 “Hey Siri” 요청의 유효성을 판단하기 위해 비교하는 데 사용됩니다. Apple은 또한 각 발화 파형의 “Hey Siri” 부분이 iPhone에 로컬로 저장되어 사용자 프로필이 iOS 업데이트에 통합된 개선된 변환을 사용할 때마다 해당 저장된 파형을 사용하여 재구성될 수 있다고 언급합니다. 논문은 또한 명시적인 등록 단계가 필요하지 않은 미래를 제안하며, 사용자가 빈 프로필에서 “Hey Siri” 기능을 시작할 수 있고, 이 프로필이 유기적으로 성장하고 업데이트될 것이라고 합니다. 그러나 현재로서는 명시적 훈련이 나중의 암묵적 훈련의 정확성을 보장하기 위한 기준선을 제공하는 데 필요하다는 것 같습니다.
Apple의 개인 정보 보호에 대한 입장을 고려할 때 놀랍지는 않지만, 모든 계산과 사용자 음성 프로필의 저장이 Apple의 서버가 아닌 각 사용자의 iPhone에서만 발생한다는 점은 주목할 만합니다. 이는 이러한 프로필이 현재 장치 간에 어떤 방식으로도 동기화되지 않음을 시사합니다.
새 게시물을 받은 편지함에서 받기
스팸은 없습니다. 언제든지 구독 해지 가능합니다.