Technologie · 3 min read · Oct 10, 2025
Über die Personalisierung von ‚Hey Siri‘ im Machine Learning Journal
In einem neuen Beitrag im Machine Learning Journal von Apple erklärt das Unternehmen, wie die Personalisierung hinter der Sprachaktivierungsfunktion „Hey Siri“ funktioniert, um die Anzahl der Fehlalarme zu reduzieren. Das Journal verweist auf einen früheren Eintrag, der den allgemeinen technischen Ansatz und die Implementierungsdetails des „Hey Siri“-Detektors sowie das allgemeinere, sprachunabhängige Problem der „Schlüsselworterkennung“ beschreibt, und beginnt damit als angenommenes Fundament für dieses neueste Papier, das sich auf die maschinellen Lerntechnologien konzentriert, die Apple bei der Entwicklung eines rudimentären Sprechererkennungssystems implementiert hat, um die Anzahl der Fehlalarme zu reduzieren, die durch andere Personen in der Nähe ausgelöst werden, die Phrasen sagen, die „Hey Siri“ ähnlich klingen.
Apple führte „Hey Siri“ mit der Einführung des iPhone 6 im Jahr 2014 ein, obwohl die Funktion ursprünglich erforderte, dass das iPhone mit einer Stromquelle verbunden war; erst mit der Einführung des iPhone 6s ein Jahr später wurde „immer aktives Hey Siri“ verfügbar, dank eines neuen, energieeffizienten Co-Prozessors, der kontinuierliches Zuhören ohne signifikanten Batterieverbrauch ermöglichen konnte. Gleichzeitig wurde die Funktion auch in iOS 9 weiter verbessert, indem ein neuer „Trainingsmodus“ hinzugefügt wurde, um Siri während der ersten Einrichtung an die Stimme des spezifischen iPhone-Nutzers zu personalisieren.
Das Papier erklärt weiter, dass der Satz „Hey Siri“ ursprünglich gewählt wurde, um so natürlich wie möglich zu sein, und fügt hinzu, dass Apple bereits vor der Einführung der Funktion festgestellt hat, dass viele Nutzer ihre Siri-Anfragen natürlich mit „Hey Siri“ begannen, nachdem sie die Home-Taste verwendet hatten, um sie zu aktivieren. Allerdings ist die „Kürze und Einfachheit der Artikulation“ des Satzes ein zweischneidiges Schwert, da sie auch das Potenzial hat, viele weitere Fehlalarme zu verursachen; wie Apple erklärt, zeigten frühe Experimente eine unakzeptabel hohe Anzahl unbeabsichtigter Aktivierungen, die unverhältnismäßig zur „angemessenen Rate“ korrekter Aufrufe waren.
Das Ziel von Apple war es daher, maschinelle Lerntechnologien zu nutzen, um die Anzahl der „False Accepts“ zu reduzieren, um sicherzustellen, dass Siri nur aufwacht, wenn der Hauptnutzer „Hey Siri“ sagt, und um insbesondere Situationen zu vermeiden, in denen eine dritte Person im Raum etwas sagt, das fälschlicherweise als Aufforderung an Siri interpretiert wird.
Apple fügt hinzu, dass „das übergeordnete Ziel“ der Sprechererkennungstechnologie darin besteht, die Identität einer Person anhand der Stimme zu bestimmen, was auf langfristige Pläne hindeutet, die zusätzliche Personalisierung und sogar Authentifizierung bieten könnten, insbesondere im Hinblick auf Mehrbenutzergeräte wie Apples HomePod. Das Ziel ist es, „wer spricht“ zu bestimmen, anstatt einfach nur zu erfassen, was gesagt wird, und das Papier erklärt weiter den Unterschied zwischen „textabhängiger Sprechererkennung“, bei der die Identifizierung auf einer bekannten Phrase basiert (wie „Hey Siri“), und der herausfordernderen Aufgabe der „textunabhängigen“ Sprechererkennung, die darin besteht, einen Benutzer unabhängig davon zu identifizieren, was er gerade sagt.
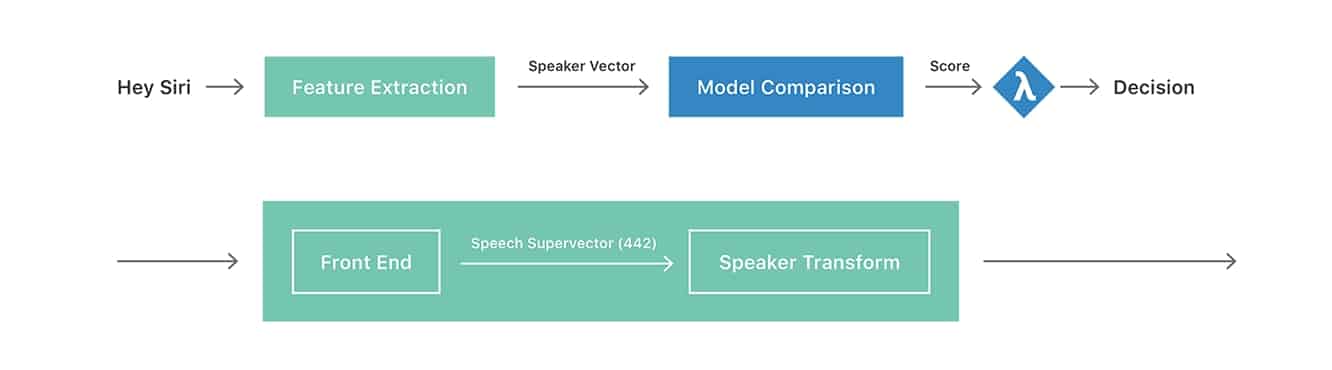
Vielleicht am interessantesten ist, dass das Journal erklärt, wie Siri weiterhin „implizit“ trainiert wird, um die Stimme eines Benutzers zu identifizieren, selbst nachdem der explizite Einschreibungsprozess (den Benutzer bitten, fünf verschiedene „Hey Siri“-Phrasen während der ersten Einrichtung zu sagen) abgeschlossen ist. Der implizite Prozess trainiert Siri weiterhin nach der ersten Einrichtung, indem er zusätzliche „Hey Siri“-Anfragen analysiert und sie dem Benutzerprofil hinzufügt, bis insgesamt 40 Proben (bekannt als „Sprechervektoren“) gespeichert sind, einschließlich der ursprünglichen fünf aus dem expliziten Trainingsprozess.
Diese Sammlung von Sprechervektoren wird dann verwendet, um zukünftige „Hey Siri“-Anfragen zu vergleichen und deren Gültigkeit zu bestimmen. Apple weist auch darauf hin, dass der „Hey Siri“-Teil jeder Äußerungswelle lokal auf dem iPhone gespeichert wird, sodass Benutzerprofile mithilfe dieser gespeicherten Wellenformen wiederhergestellt werden können, wann immer verbesserte Transformationen in iOS-Updates integriert werden. Das Papier postuliert auch eine Zukunft, in der kein expliziter Einschritt erforderlich sein wird und Benutzer einfach die Funktion „Hey Siri“ von einem leeren Profil aus nutzen können, das organisch wächst und aktualisiert wird. Derzeit scheint es jedoch, dass das explizite Training notwendig ist, um eine Basislinie zu schaffen, die die Genauigkeit des späteren impliziten Trainings sicherstellt.
Obwohl es nicht überraschend ist, angesichts von Apples Haltung zur Privatsphäre, ist es dennoch erwähnenswert, dass all diese Berechnungen und die Speicherung des Sprachprofils des Benutzers ausschließlich auf dem iPhone jedes Benutzers erfolgen, und nicht auf einem der Server von Apple, was darauf hindeutet, dass solche Profile derzeit nicht zwischen Geräten synchronisiert werden.
Erhalte neue Beiträge in deinem Posteingang.
Kein Spam. Jederzeit abmelden.