Betrugsprävention · 10 min read · Feb 09, 2026
Von Missbrauch von kostenlosen Testversionen bis hin zu Promo-Stacking: Wie KI den Kampf gegen Abonnementbetrug anführt

Abonnementbetrug verhält sich nicht wie Betrug – deshalb übersehen die meisten Systeme ihn. Es sind nicht mehr nur gekennzeichnete Karten oder plötzliche Verkaufsanstiege – es sind geghostete kostenlose Testversionen, Promo-Stacking und koordinierte Geräte-Spoofing, die tatsächliches Nutzerverhalten nachahmen.
Ich bin Divesh Singh Sai, ein Senior Software Engineer mit über einem Jahrzehnt Erfahrung im Aufbau von Betrugspräventionssystemen für hochskalierte digitale Zahlungsplattformen – wo jede Millisekunde zählt und jede Transaktion ein Risiko darstellen könnte.
In diesem Artikel erkläre ich, wie wir adaptive Betrugsabwehr für Abonnementzahlungen unter Verwendung von überwachten Lernen, Anomalieerkennung und Verhaltensmodellierung aufgebaut haben.
Wenn Sie Betrugssysteme in großem Maßstab aufbauen oder versuchen, zu verstehen, wie KI Bedrohungen aufdeckt, die im Klartext verborgen sind – dieser Leitfaden gibt Ihnen die technischen Muster und Strategien, die in der Produktion funktionieren.
Wie meine Arbeit den Fokus auf Abonnementbetrug lenkte
Mein Interesse an KI-gestützter Betrugserkennung begann nicht in der Theorie – es begann in der Produktion.
Während ich an Zahlungsdiensten arbeitete, nahm ich die Herausforderung an, die Fähigkeit der Plattform zur Erkennung ungewöhnlichen Zahlungsverhaltens zu verbessern.
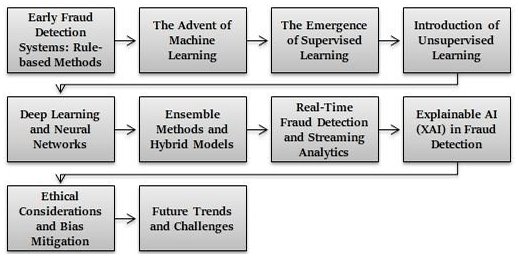
Das Projekt begann mit regelbasierten Systemen, bei denen wir Transaktionen anhand vordefinierter Bedingungen kennzeichneten: mehrere fehlgeschlagene Zahlungen, ungewöhnliche Geräteorte oder schnelles Kontowechseln.
Als der Dienst jedoch global skalierte und die Betrüger raffinierter wurden, wurden diese statischen Regeln zu Haftungen.
Ein herausragendes Beispiel ist, als wir einen Anstieg des Missbrauchs von kostenlosen Testversionen bemerkten. Nutzer erstellten mehrere Konten über Geräte und Regionen hinweg und nutzten Werbecodes und regionale Preisunterschiede aus.
Da diese Aktionen keine einzelnen Regeln verletzten, schlüpften sie durch die Maschen. Das war der Moment, als wir sahen, wie schnell Regeln zu Haftungen werden konnten.
Als Reaktion darauf half ich, Initiativen zu leiten, die KI und ML nutzten, um nuanciertere Muster zu erfassen. Wir implementierten Betrugsprüfungs-Schichten, die in der Lage waren, Verhalten über Konten und Geräte hinweg zu verfolgen und Anomalien zu identifizieren, die auf der Ebene einzelner Transaktionen nicht offensichtlich waren.
Diese Transformation, die Browser-, TV- und mobile Plattformen umfasste, trieb mich dazu, modernste ML-Techniken zu erkunden – insbesondere solche, die in Echtzeit arbeiten und massive Datenmengen verarbeiten konnten.
Warum traditionelle Systeme bei der Erkennung von Abonnementbetrug versagen
Entwickler entwarfen ursprünglich konventionelle Betrugserkennungsmethoden – wie statische Regel-Engines, statistische Modelle und Blocklisten – für einfachere Anwendungsfälle.
Diese Methoden funktionieren gut, wenn Muster vorhersehbar sind, wie zum Beispiel bei der Erkennung eines plötzlichen Anstiegs des Transaktionsvolumens oder einer verdächtigen IP-Adresse.
Allerdings führen Abonnementdienste zu fortlaufenden Beziehungen zwischen Nutzern und Plattformen, was bedeutet, dass betrügerisches Verhalten oft über einen längeren Zeitraum gestreckt und als reguläre Aktivität getarnt ist.
Ein Betrüger könnte beispielsweise eine gestohlene Karte verwenden, um ein Abonnement zu starten, Inhalte zu konsumieren und einen Chargeback einen Monat später einzuleiten.
Oder sie könnten ein legitimes Konto übernehmen, die Zahlungsmethode ändern und stillschweigend mehrere Zusatzabonnements hinzufügen. Regelbasierte Systeme übersehen oft diese schleichenden Angriffe, da sie auf sofortige Warnsignale und nicht auf Verhaltensmuster angewiesen sind.
Ich habe dies aus erster Hand erlebt, während ich an Betrugspräventionssystemen arbeitete. Wir hatten Fälle, in denen böse Akteure Abonnementverlängerungen, Testfenster und Gerätegrenzen auf eine Weise manipulierten, die mit Regeln allein nicht erkennbar war.
Diese Misserfolge frustrierten die Nutzer und untergruben das Vertrauen der Kunden, was oft unnötige Supportinterventionen auslöste.
Das war nicht nur unsere Erfahrung. Ein SSRN-Papier über künstliche Intelligenz in Finanzdienstleistungen hebt die Unfähigkeit statischer Systeme hervor, sich an sich entwickelnde Betrugstechniken anzupassen. Diese Erkenntnisse stimmen stark mit dem überein, was ich in der Praxis beobachtet habe.
Wie wir KI nutzen, um Betrug zu erkennen, den Sie nie kommen sehen werden

„Vieles von dem, was wir mit maschinellem Lernen tun, geschieht unter der Oberfläche. Maschinelles Lernen treibt unsere Algorithmen für Nachfrageprognosen, Produkt-Suchrankings, Produkt- und Angebotsempfehlungen, Merchandising-Platzierungen, Betrugserkennung, Übersetzungen und vieles mehr an.“ — Jeff Bezos, über Four.co.uk
Dieses Zitat spiegelt wider, was ich aus erster Hand in meiner Arbeit gesehen habe. Die effektivsten Systeme für maschinelles Lernen arbeiten oft leise im Hintergrund – aber sie sind entscheidend, insbesondere bei der Betrugserkennung.
In Abonnementzahlungssystemen sahen wir, dass kein einzelner Algorithmus die Komplexität des Abonnementbetrugs lösen konnte. Wir wechselten von statischen regelbasierten Systemen zu geschichteten, ML-gesteuerten Ansätzen, die jeweils ein anderes Betrugsmuster ansprachen.
Dies ermöglichte es uns, verhaltensbasierte Anomalien in Echtzeit zu erkennen, anstatt uns auf vorhersehbare Regeltrigger zu verlassen.
Überwachtes Lernen zur Betrugserkennung
Überwachtes Lernen spielte eine grundlegende Rolle in unserer Betrugs-Pipeline. Wir verwendeten Algorithmen wie Entscheidungsbäume, Random Forests und Gradient Boosting Machines, um Transaktionen basierend auf bekannten Betrugsmustern zu klassifizieren.
Wir trainierten diese Modelle mit gekennzeichneten Daten – Fällen, die wir bereits als betrügerisch oder legitim identifiziert hatten – und verwendeten sie, um wiederholte Verhaltensweisen wie Abonnement-Stacking und Testen von Zahlungsmethoden lange bevor eine menschliche Überprüfung erfolgen konnte, zu erkennen.
Eine Studie von GSCARR unterstützt diesen Ansatz und zeigt, dass überwachte Modelle die Anzahl der falsch positiven Ergebnisse erheblich reduzieren und die Präzision der Betrugserkennung auf hochvolumigen Plattformen wie digitalem Banking und Streaming-Diensten verbessern.
Unüberwachtes Lernen zur Anomalieerkennung
Einige Betrügereien wiederholen sich nicht. Sie mutieren.
Wir wandten uns dem unüberwachten Lernen zu und verwendeten Methoden wie Autoencoders, K-Means-Clustering und Isolation Forests, um Anomalien zu identifizieren, ohne gekennzeichnete Daten zu benötigen.
Diese Modelle halfen, aufkommende Bedrohungen zu erkennen, wie koordinierte Promo-Missbräuche – indem sie Ausreißer im Verhalten erkannten, wie wiederholte Testanmeldungen von leicht veränderten Geräte-IDs.
Ein Forschungsbericht, veröffentlicht von ESP-IJACT, zeigte, dass diese unüberwachten Modelle die manuelle Betrugsüberprüfung reduzierten, indem sie zuvor ungesehene Betrugszeichen erfassten, die konventionelle Systeme oft übersehen.
Echtzeiterkennung mit Deep Learning
Deep Learning war entscheidend für die Verarbeitung komplexer, zeitlich sequenzierter Verhaltensweisen in Echtzeit. Wir verwendeten rekurrente neuronale Netze (RNNs) und konvolutionale neuronale Netze (CNNs), um Nutzeraktionen über die Zeit zu überwachen und zu verfolgen, wie Nutzer browsen, abonnieren, Geräte wechseln oder sich aus neuen Regionen anmelden.
Diese Modelle verarbeiteten Benutzerreisen – Anmelden, Browsen, Abonnieren, Geräte wechseln, Abbrechen – und kennzeichneten alles, was den erwarteten Fluss störte.
Laut IJFMR können Deep-Learning-Modelle Inferenzgeschwindigkeiten von unter 50 ms in der Produktion liefern, was eine Betrugserkennung ermöglicht, ohne Verzögerungen in das Benutzererlebnis einzuführen. Diese Leistung entsprach unserer Erfahrung bei der Bereitstellung von Modellen über AWS Lambda für die Echtzeitinferenz.
Verhaltensanalytik und Nutzerprofilierung
Eine weitere wichtige Schicht der Erkennung kam aus der Verhaltensanalytik. Wir verwendeten versteckte Markov-Modelle (HMMs) und Long Short-Term Memory (LSTM)-Netzwerke, um das Nutzerverhalten über die Zeit zu profilieren.
Wir profilierten das Verhalten anhand von Anmelde-Mustern, Gerätegewohnheiten und Sitzungsdauern. Dies half uns, Unterschiede zwischen echten Nutzern und Betrügern zu erkennen, insbesondere solchen, die sich hinter VPNs oder Emulatoren versteckten.
Die Verhaltensmodellierung war besonders entscheidend zum Schutz von Benutzerkonten über Streaming-Geräte und -Plattformen hinweg, wo betrügerische Aktivitäten oft das legitime Nutzerverhalten eng widerspiegelten.
Graphbasierte Betrugserkennung
Um koordinierten Betrug zu erkennen, führten wir Graph Neural Networks (GNNs) ein. Diese Modelle kartierten Beziehungen zwischen Nutzern, Geräten, IP-Adressen und Zahlungsmethoden.
In einem Fall entdeckten wir ein Betrugsnetzwerk, das Werbecodes ausnutzte, indem wir Dutzende scheinbar nicht zusammenhängender Konten verknüpften, die Zahlungsfingerabdrücke und Geräte-IDs teilten.
Dieser graphbasierte Ansatz half, großangelegten, organisierten Missbrauch aufzudecken, der oft für traditionelle regelbasierte Systeme unsichtbar war. Es wurde eines der wirkungsvollsten Upgrades für unseren Erkennungsstapel, insbesondere in einer Abonnementumgebung, in der böse Akteure zusammenarbeiten, um Plattformgrenzen zu umgehen.
Was es braucht, um KI-Betrugserkennung in großem Maßstab zu betreiben
Die Übersetzung von KI-Modellen von der Theorie in die Praxis war ein zentraler Bestandteil meiner Arbeit in Abonnementzahlungssystemen.
Neben der Auswahl der richtigen Modelle mussten wir sicherstellen, dass unsere Systeme in der Lage waren, in großem Maßstab zu arbeiten, massive Datenmengen zu verarbeiten und Echtzeiteinblicke zu liefern, ohne das Kundenerlebnis zu unterbrechen.
Dies umfasste alles von der Merkmalsentwicklung bis zur cloudbasierten Bereitstellung und ständiger Iteration basierend auf Live-Daten.
Datensammlung und Merkmalsentwicklung
Wir bauten unsere Betrugsmodelle auf hochwertigen Daten auf. Wir sammelten verschiedene Metadaten, wie Transaktionswert, Zeitstempel, IP-Geolokalisierung, Geräte-ID und Nutzerverhalten über Sitzungen und Geräte hinweg. Für abonnementspezifische Einblicke entwickelten wir Merkmale wie:
Transaktionsgeschwindigkeit über kurze Zeiträume
Geräteverwendungskonsistenz über Konten hinweg
Zahlungsmethodenlebensdauer und Wechselverhalten
Abonnementlebenszyklusmuster (z. B. Reaktivierungen nach kostenlosen Testversionen)
Im Rahmen von unternehmensgerechten Ingenieur- und Compliance-Standards stellten wir auch sicher, dass diese Daten anonymisiert und konform mit internen Datenschutzrichtlinien und regionalen Vorschriften blieben.
Modelltraining und -bewertung
In meiner Rolle, die Betrugserkennungsinitiativen leitet, übersetzte ich Geschäftssignale in skalierbare, modellbereite Merkmale zur Unterstützung der Betrugserkennung.
Wir arbeiteten mit großen Mengen an Produktions-Transaktionsdaten, die durch Metadaten angereichert waren und Verhaltensindikatoren wie Geräte-Konsistenz, Häufigkeit des Zahlungsmethodenwechsels und Nutzung von Werbecodes erfassten.
Ich stimmte unsere Signale mit tatsächlichem Abonnementmissbrauch ab, wie z. B. Testwiederverwendung und koordiniertes Promo-Stacking. Diese Erkenntnisse informierten die Modelle, die wir in unseren Zahlungsprüfungs-Systemen einsetzten.
Die Nutzung kontextueller Merkmale aus dem Nutzerverhalten, anstatt sich ausschließlich auf Transaktionswerte zu verlassen, verbessert die Leistung der KI-gestützten Betrugserkennung erheblich.
Nach der Bereitstellung überwachten wir genau, wie die Modelle in Live-Umgebungen abschnitten. Ich konzentrierte mich darauf, sicherzustellen, dass die Betrugs-Pipeline mit den Produktziele für das Nutzererlebnis übereinstimmte und sich anpasste, während sich das Nutzerverhalten und die Betrugsmuster entwickelten. Dies half uns, eine starke Betrugsabdeckung sicherzustellen, während wir ein nahtloses Erlebnis für legitime Nutzer bewahrten.
Integration mit Zahlungssystemen
Die Betrugserkennung musste auch in Echtzeit funktionieren. Wir setzten Modelle in der Produktion mit den folgenden Mitteln ein:
AWS Lambda, für schnelle Inferenz
DynamoDB, um Risikobewertungen zu speichern und abzurufen
Mikrodienste und APIs, um gekennzeichnete Fälle zu routen
Kafka, für Streaming und Skalierung über Regionen hinweg
Diese Architektur stellte sicher, dass unser System Bedrohungen kennzeichnen konnte, bevor die Transaktion abgeschlossen wurde, während es für alle außer dem Betrüger unsichtbar blieb.

Kontinuierliches Lernen und Anpassung
Betrüger entwickeln sich weiter, und das müssen auch unsere Systeme. Wir implementierten Feedbackschleifen, die von Analysten bestätigte Betrugsfälle aufnahmen und das Modellverhalten entsprechend anpassten.
In ausgewählten Projekten erkundeten wir auch Ansätze des verstärkten Lernens, die nicht nur für die Betrugsfangrate optimierten, sondern auch für die Minimierung langfristiger falsch positiver Ergebnisse.
Zukünftige Trends in der KI-gestützten Betrugsprävention

Innovationen, die Transparenz, Zusammenarbeit und Datenintegrität priorisieren, gestalten die Zukunft der Betrugserkennung, während sie die Geschwindigkeit und Skalierung aufrechterhalten, die von Abonnementplattformen gefordert werden.
Erklärbare KI (XAI)
Der schwierigste Teil von KI ist nicht, sie zu bauen. Es ist zu erklären, warum sie eine Entscheidung getroffen hat.
Stakeholder – von Compliance-Beauftragten bis zu Kundenserviceteams – müssen verstehen, warum eine Transaktion gekennzeichnet wurde. Erklärbare KI ermöglicht es uns, die Gründe hinter jeder Betrugsentscheidung zu liefern.
Laut Science Times (2024) beschleunigt sich die Nachfrage nach transparenten KI-Modellen, da Institutionen nach Werkzeugen suchen, die die Einhaltung von Vorschriften und das Vertrauen der Kunden unterstützen.
Föderiertes Lernen
In globalen Organisationen sind Daten oft siloartig oder unterliegen regionalen Datenschutzgesetzen. Föderiertes Lernen adressiert dies, indem Modelle über verteilte Datenquellen trainiert werden, ohne die Daten zu verschieben. Es ermöglicht eine kollaborative Betrugsabwehr, während die Privatsphäre der Nutzer geschützt wird.
Es ist ein Modell, das wir begonnen haben zu erkunden, um die Betrugssignale über Dienste hinweg zu stärken, ohne sensible Nutzerdaten offenzulegen oder zu zentralisieren.
Blockchain-basierte Betrugsprävention
Obwohl sie noch in der Entwicklung ist, bietet Blockchain ein überzeugendes Potenzial zur Sicherung der Transaktionsintegrität. Durch die Verwendung dezentraler Ledger wird sichergestellt, dass jede Transaktion überprüfbar, manipulationssicher und nachverfolgbar ist – entscheidend zur Verhinderung von identitätsbasiertem Abonnementbetrug und Diebstahl digitaler Vermögenswerte.
Wohin sich der Abonnementbetrug als Nächstes entwickelt (und wie man sich vorbereitet)
Betrug bei abonnementbasierten digitalen Zahlungen wächst und wird raffinierter. Vom Missbrauch kostenloser Testversionen bis hin zu Social Engineering entwickeln Betrüger ihre Taktiken schnell weiter.
In meiner Arbeit, die Betrugsprüfungen für Abonnementzahlungsplattformen leitet, habe ich aus erster Hand gesehen, wie traditionelle Systeme versagen und wie KI und maschinelles Lernen die Erkennung transformieren können.
Durch die Verwendung von überwachten und unüberwachten Lernansätzen, Verhaltensmodellierung und Graphanalyse haben wir skalierbare Lösungen entwickelt, die sich in Echtzeit anpassen.
Effektive Betrugsprävention erfordert jedoch mehr als nur innovative Werkzeuge. Es braucht Vision – die Vision, adaptive, transparente Systeme zu schaffen, die sowohl Kunden als auch Geschäftsergebnisse schützen.
Wenn Sie darauf warten, zu handeln, sind Sie bereits im Rückstand.
Referenzen:
Adaboina, S.R., (2024). KI und ML in der Betrugserkennung: Wie Algorithmen Kriminelle fangen. Science Times. https://www.sciencetimes.com/articles/60131/20241216/ai-ml-fraud-detection.htm
Chopra, P. und Binwal, A., (2024). Sicherheit und Betrugserkennung in digitalen Zahlungen mit maschinellem Lernen verbessern. International Journal for Multidisciplinary Research, 6(6). https://www.ijfmr.com/papers/2024/6/30337.pdf
Mahapatra, B.G., (2024). KI und maschinelles Lernen in der Betrugserkennung. ESP International Journal of Advancements in Computational Technology, 2(4), S.125–139. https://www.espjournals.org/IJACT/2024/Volume2-Issue4/IJACT-V2I4P117.pdf
Olowu, O., Adeleye, A.O., Omokanye, A.O., Ajayi, A.M., Adepoju, A.O., Omole, O.M. und Chianumba, E.C., (2024). KI-gesteuerte Betrugserkennung im Bankwesen: Eine systematische Überprüfung der Datenwissenschaftsansätze zur Verbesserung der Cybersicherheit. GSC Advanced Research and Reviews, 21 (2), S.227–237. https://gsconlinepress.com/journals/gscarr/sites/default/files/GSCARR-2024-0418.pdf
Patil, D., (2024). Künstliche Intelligenz in Finanzdienstleistungen: Risikomanagement und Betrugserkennung. SSRN Electronic Journal. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5057412
Diese Geschichte wurde ursprünglich am 14. August 2024 veröffentlicht.
Erhalte neue Beiträge in deinem Posteingang.
Kein Spam. Jederzeit abmelden.