Fraude par abonnement · 13 min read · Feb 09, 2026
De l'abus d'essai gratuit à l'accumulation de promotions : comment l'IA mène la lutte contre la fraude par abonnement

La fraude par abonnement ne se comporte pas comme une fraude—c’est pourquoi la plupart des systèmes la manquent. Ce ne sont plus des cartes signalées ou des pics de ventes flash—ce sont des essais gratuits fantômes, des accumulations de promotions et des usurpations d’appareils coordonnées qui imitent le comportement réel des utilisateurs.
Je suis Divesh Singh Sai, ingénieur logiciel senior avec plus d’une décennie d’expérience dans la construction de systèmes de prévention de la fraude pour des plateformes de paiement numérique à grande échelle—où chaque milliseconde compte et chaque transaction pourrait être un risque.
Dans cet article, j’expliquerai comment nous avons construit des défenses adaptatives contre la fraude pour les paiements par abonnement en utilisant l’apprentissage supervisé, la détection d’anomalies et la modélisation comportementale.
Si vous construisez des systèmes de fraude à grande échelle—ou essayez de comprendre comment l’IA découvre des menaces cachées à la vue de tous—ce guide vous donnera les modèles techniques et les stratégies qui fonctionnent en production.
Comment mon travail a suscité un intérêt pour la fraude par abonnement
Mon intérêt pour la détection de fraude alimentée par l’IA n’a pas commencé dans la théorie—il a commencé en production.
En travaillant sur des services de paiement, j’ai relevé le défi d’améliorer la capacité de la plateforme à détecter des comportements de paiement inhabituels.
Le projet a commencé avec des systèmes basés sur des règles, où nous signalions les transactions en utilisant des conditions prédéfinies : plusieurs paiements échoués, emplacements d’appareils inhabituels ou changements rapides de compte.
Cependant, à mesure que le service se développait à l’échelle mondiale et que les fraudeurs devenaient plus sophistiqués, ces règles statiques sont devenues des responsabilités.
Un exemple marquant est lorsque nous avons remarqué une augmentation de l’abus d’essai gratuit. Les utilisateurs créaient plusieurs comptes sur différents appareils et régions, exploitant des codes promotionnels et des écarts de prix régionaux.
Parce que ces actions ne violaient aucune règle individuelle, elles ont échappé aux mailles du filet. C’est alors que nous avons vu à quelle vitesse les règles devenaient des responsabilités.
En réponse, j’ai aidé à diriger des initiatives qui utilisaient l’IA et le ML pour attraper des motifs plus nuancés. Nous avons mis en œuvre des couches de filtrage de fraude capables de suivre le comportement à travers les comptes et les appareils, identifiant des anomalies qui n’étaient pas évidentes au niveau de la transaction individuelle.
Cette transformation, qui s’étendait aux plateformes de navigateur, de télévision et mobiles, m’a poussé à explorer des techniques de ML à la pointe de la technologie—en particulier celles qui pouvaient fonctionner en temps réel et gérer des volumes de données massifs.
Pourquoi les systèmes traditionnels échouent dans la détection de la fraude par abonnement
Les développeurs ont initialement conçu des méthodes de détection de fraude conventionnelles—comme les moteurs de règles statiques, les modèles statistiques et les listes noires—pour des cas d’utilisation plus simples.
Ces méthodes fonctionnent bien lorsque les motifs sont prévisibles, comme la détection d’une augmentation soudaine du volume des transactions ou d’une adresse IP suspecte.
Cependant, les services d’abonnement introduisent des relations continues entre les utilisateurs et les plateformes, ce qui signifie que le comportement frauduleux est souvent étalé dans le temps et déguisé en activité régulière.
Par exemple, un fraudeur pourrait utiliser une carte volée pour commencer un abonnement, consommer du contenu et initier un rétrofacturation un mois plus tard.
Ou ils pourraient prendre le contrôle d’un compte légitime, changer le mode de paiement et ajouter discrètement plusieurs abonnements supplémentaires. Les systèmes basés sur des règles manquent souvent ces attaques à combustion lente parce qu’ils s’appuient sur des signaux d’alerte immédiats plutôt que sur des tendances comportementales.
J’ai rencontré cela de première main en travaillant sur des systèmes de prévention de la fraude. Nous avions des cas où des acteurs malveillants manipulaient les renouvellements d’abonnement, les fenêtres d’essai et les limites d’appareils de manière qui n’étaient pas détectables avec des règles seules.
Ces échecs ont frustré les utilisateurs et érodé la confiance des clients, déclenchant souvent des interventions de support inutiles.
Ce n’était pas seulement notre expérience. Un article SSRN sur l’intelligence artificielle dans les services financiers souligne l’incapacité des systèmes statiques à s’adapter aux techniques de fraude évolutives. Ces résultats s’alignent fortement avec ce que j’ai observé dans la pratique.
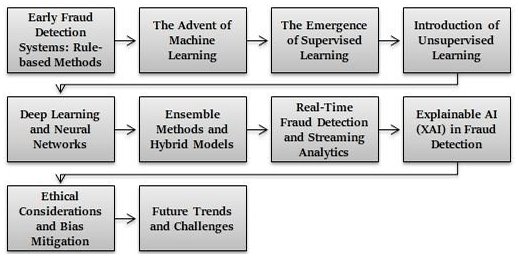
Comment nous utilisons l’IA pour attraper la fraude que vous ne verrez jamais venir

“Une grande partie de ce que nous faisons avec l’apprentissage automatique se passe sous la surface. L’apprentissage automatique alimente nos algorithmes pour la prévision de la demande, le classement des recherches de produits, les recommandations de produits et d’offres, les placements de marchandises, la détection de la fraude, les traductions, et bien plus encore.” — Jeff Bezos, via Four.co.uk
Cette citation reflète ce que j’ai vu de première main dans mon travail. Les systèmes d’apprentissage automatique les plus efficaces fonctionnent souvent discrètement en arrière-plan—mais ils sont critiques, surtout dans la détection de la fraude.
Dans les systèmes de paiement par abonnement, nous avons constaté qu’aucun algorithme unique ne pouvait résoudre les complexités de la fraude par abonnement. Nous avons évolué d’un système basé sur des règles statiques à des approches multicouches, pilotées par le ML, chacune abordant un motif de fraude différent.
Cela nous a permis de détecter des anomalies basées sur le comportement en temps réel plutôt que de nous fier à des déclencheurs de règles prévisibles.
Apprentissage supervisé pour la détection de la fraude
L’apprentissage supervisé a joué un rôle fondamental dans notre pipeline de fraude. Nous avons utilisé des algorithmes tels que les arbres de décision, les forêts aléatoires et les machines à gradient boosting pour classer les transactions en fonction de motifs de fraude connus.
Nous avons formé ces modèles sur des données étiquetées—des cas que nous avions déjà identifiés comme frauduleux ou légitimes—et les avons utilisés pour repérer des comportements répétitifs comme l’accumulation d’abonnements et les tests de méthodes de paiement bien avant qu’un examen humain puisse intervenir.
Une étude de GSCARR soutient cette approche, montrant que les modèles supervisés réduisent considérablement les faux positifs et améliorent la précision de la détection de la fraude dans des plateformes à fort volume comme la banque numérique et les services de streaming.
Apprentissage non supervisé pour la détection d’anomalies
Certaines fraudes ne se répètent pas. Elles mutent.
Nous nous sommes tournés vers l’apprentissage non supervisé, utilisant des méthodes comme les autoencodeurs, le clustering K-Means et les forêts d’isolement pour identifier des anomalies sans nécessiter de données étiquetées.
Ces modèles ont aidé à faire émerger des menaces, telles que l’abus de promotions coordonnées—en repérant des valeurs aberrantes dans le comportement, comme des inscriptions répétées à des essais à partir d’ID d’appareil légèrement modifiés.
Un article de recherche publié par ESP-IJACT a montré que ces modèles non supervisés réduisaient l’examen manuel de la fraude en attrapant des signaux de fraude auparavant invisibles que les systèmes conventionnels manquent souvent.
Détection en temps réel avec l’apprentissage profond
L’apprentissage profond était essentiel pour gérer des comportements complexes et séquencés dans le temps. Nous avons utilisé des réseaux de neurones récurrents (RNN) et des réseaux de neurones convolutifs (CNN) pour surveiller les actions des utilisateurs au fil du temps, suivant comment les utilisateurs naviguaient, s’abonnaient, changeaient d’appareil ou se connectaient depuis de nouvelles régions.
Ces modèles ont traité les parcours des utilisateurs—connexion, navigation, abonnement, changement d’appareil, annulation—et ont signalé tout ce qui rompait le flux attendu.
Selon IJFMR, les modèles d’apprentissage profond peuvent fournir des vitesses d’inférence inférieures à 50 ms en production, permettant la détection de la fraude sans introduire de latence dans l’expérience utilisateur. Cette performance correspondait à notre expérience de déploiement de modèles via AWS Lambda pour une inférence en temps réel.
Analyse comportementale et profilage des utilisateurs
Une autre couche clé de détection provenait de l’analyse comportementale. Nous avons utilisé des modèles de Markov cachés (HMM) et des réseaux de mémoire à long et court terme (LSTM) pour profiler le comportement des utilisateurs au fil du temps.
Nous avons profilé le comportement à travers les motifs de connexion, les habitudes d’appareil et la durée des sessions. Cela nous a aidés à repérer les différences entre les vrais utilisateurs et les fraudeurs, en particulier ceux se cachant derrière des VPN ou des émulateurs.
La modélisation comportementale était particulièrement critique pour protéger les comptes des utilisateurs sur les appareils et plateformes de streaming, où l’activité frauduleuse imite souvent de près le comportement légitime des utilisateurs.
Détection de fraude basée sur les graphes
Pour détecter la fraude coordonnée, nous avons introduit des réseaux de neurones graphiques (GNN). Ces modèles ont cartographié les relations entre les utilisateurs, les appareils, les adresses IP et les méthodes de paiement.
Dans un cas, nous avons découvert un réseau de fraude exploitant des codes promotionnels en reliant des dizaines de comptes apparemment non liés partageant des empreintes de paiement et des ID d’appareil.
Cette approche basée sur les graphes a aidé à révéler des abus organisés à grande échelle, souvent invisibles aux systèmes basés sur des règles traditionnelles. Elle est devenue l’une des mises à jour les plus impactantes de notre pile de détection, surtout dans un environnement d’abonnement où les acteurs malveillants collaborent pour contourner les limites de la plateforme.
Ce qu’il faut pour faire fonctionner la détection de fraude par IA à grande échelle
La traduction des modèles d’IA de la théorie à la pratique était une partie essentielle de mon travail dans les systèmes de paiement par abonnement.
Au-delà de la sélection des bons modèles, nous devions nous assurer que nos systèmes pouvaient fonctionner à grande échelle, gérer des volumes de données massifs et fournir des informations en temps réel, sans interrompre l’expérience client.
Cela impliquait tout, de l’ingénierie des fonctionnalités au déploiement basé sur le cloud et à l’itération constante basée sur des données en direct.
Collecte de données et ingénierie des fonctionnalités
Nous avons construit nos modèles de fraude sur des données de haute qualité. Nous avons collecté diverses métadonnées, telles que la valeur des transactions, les horodatages, la géolocalisation IP, l’ID d’appareil et le comportement des utilisateurs à travers les sessions et les appareils. Pour des informations spécifiques aux abonnements, nous avons conçu des fonctionnalités telles que :
Vélocité des transactions sur de courtes fenêtres
Cohérence d’utilisation des appareils à travers les comptes
Durée de vie et comportement de changement de méthode de paiement
Modèles de cycle de vie d’abonnement (par exemple, réactivations après des essais gratuits)
Dans le cadre des normes d’ingénierie de niveau entreprise et de conformité, nous avons également veillé à ce que ces données restent anonymisées et conformes aux politiques de confidentialité internes et aux réglementations régionales.
Formation et évaluation des modèles
Dans mon rôle de leader des initiatives de détection de fraude, j’ai traduit les signaux commerciaux en fonctionnalités prêtes à être modélisées pour soutenir la détection de la fraude.
Nous avons travaillé avec de grands volumes de données de transactions de production enrichies par des métadonnées, capturant des indicateurs comportementaux tels que la cohérence des appareils, la fréquence de changement de paiement et l’utilisation de codes promotionnels.
J’ai aligné nos signaux avec les abus d’abonnement réels, tels que le recyclage d’essais et l’accumulation de promotions coordonnées. Ces informations ont informé les modèles que nous avons déployés dans nos systèmes de filtrage de paiements.
Exploiter des fonctionnalités contextuelles provenant du comportement des utilisateurs, plutôt que de s’appuyer uniquement sur les valeurs des transactions, améliore considérablement les performances de la détection de fraude basée sur l’IA.
Après le déploiement, nous avons étroitement surveillé la performance des modèles dans des environnements en direct. Je me suis concentré sur l’assurance que le pipeline de fraude s’alignait sur les objectifs d’expérience produit, en s’adaptant à mesure que le comportement des utilisateurs et les motifs de fraude évoluaient. Cela nous a aidés à garantir une couverture solide contre la fraude tout en préservant une expérience fluide pour les utilisateurs légitimes.
Intégration avec les systèmes de paiement
La détection de la fraude devait également fonctionner en temps réel. Nous avons déployé des modèles en production en utilisant les éléments suivants :
AWS Lambda, pour une inférence rapide
DynamoDB, pour stocker et récupérer les scores de risque
Microservices et API pour acheminer les cas signalés
Kafka, pour le streaming et la mise à l’échelle à travers les régions
Cette architecture a assuré que notre système pouvait signaler des menaces avant que la transaction ne soit complétée tout en restant invisible pour tous sauf le fraudeur.

Apprentissage et adaptation continus
Les fraudeurs évoluent, et nos systèmes doivent donc évoluer aussi. Nous avons mis en œuvre des boucles de rétroaction qui ingéraient des cas de fraude confirmés par des analystes et ajustaient le comportement des modèles en conséquence.
Dans certains projets, nous avons également exploré des approches d’apprentissage par renforcement qui optimisaient non seulement le taux de détection de fraude, mais aussi la minimisation des faux positifs à long terme.
Tendances futures dans la prévention de la fraude alimentée par l’IA

Les innovations priorisant la transparence, la collaboration et l’intégrité des données façonnent l’avenir de la détection de la fraude tout en maintenant la vitesse et l’échelle exigées par les plateformes d’abonnement.
IA explicable (XAI)
La partie la plus difficile de l’IA n’est pas de la construire. C’est d’expliquer pourquoi elle a pris une décision.
Les parties prenantes—des agents de conformité aux équipes de service client—doivent comprendre pourquoi une transaction a été signalée. L’IA explicable nous permet de fournir le raisonnement derrière chaque décision de fraude.
Selon Science Times (2024), la demande de modèles d’IA transparents s’accélère, les institutions recherchant des outils soutenant la conformité réglementaire et la confiance des clients.
Apprentissage fédéré
Dans les organisations mondiales, les données sont souvent cloisonnées ou régies par des lois de confidentialité régionales. L’apprentissage fédéré aborde cela en formant des modèles à travers des sources de données distribuées sans déplacer les données. Cela rend la défense collaborative contre la fraude possible tout en protégeant la vie privée des utilisateurs.
C’est un modèle que nous avons commencé à explorer au sein de systèmes à grande échelle pour renforcer les signaux de fraude à travers les services, sans exposer ou centraliser des données sensibles des utilisateurs.
Prévention de la fraude basée sur la blockchain
Bien qu’encore émergente, la blockchain offre un potentiel convaincant pour sécuriser l’intégrité des transactions. L’utilisation de registres décentralisés garantit que chaque transaction est vérifiable, à l’abri des falsifications et traçable—vital pour prévenir la fraude par abonnement basée sur l’identité et le vol d’actifs numériques.
Où la fraude par abonnement se dirige-t-elle ensuite (et comment se préparer)
La fraude dans les paiements numériques basés sur l’abonnement est en croissance et devient plus sophistiquée. De l’abus d’essai gratuit à l’ingénierie sociale, les fraudeurs évoluent rapidement leurs tactiques.
Dans mon travail de direction du filtrage de fraude pour les plateformes de paiement par abonnement, j’ai vu de première main comment les systèmes traditionnels échouent et comment l’IA et l’apprentissage automatique peuvent transformer la détection.
En utilisant des approches d’apprentissage supervisé et non supervisé, la modélisation comportementale et l’analyse graphique, nous avons construit des solutions évolutives qui s’adaptent en temps réel.
Cependant, une prévention efficace de la fraude nécessite plus que de simples outils innovants. Cela demande une vision—une vision pour créer des systèmes adaptatifs et transparents qui protègent à la fois les clients et les résultats commerciaux.
Si vous attendez d’agir, vous êtes déjà en retard.
Références :
Adaboina, S.R., (2024). IA et ML dans la détection de fraude : comment les algorithmes attrapent les criminels. Science Times. https://www.sciencetimes.com/articles/60131/20241216/ai-ml-fraud-detection.htm
Chopra, P. et Binwal, A., (2024). Améliorer la sécurité et la détection de la fraude dans les paiements numériques en utilisant l’apprentissage automatique. International Journal for Multidisciplinary Research, 6(6). https://www.ijfmr.com/papers/2024/6/30337.pdf
Mahapatra, B.G., (2024). IA et apprentissage automatique dans la détection de fraude. ESP International Journal of Advancements in Computational Technology, 2(4), pp.125–139. https://www.espjournals.org/IJACT/2024/Volume2-Issue4/IJACT-V2I4P117.pdf
Olowu, O., Adeleye, A.O., Omokanye, A.O., Ajayi, A.M., Adepoju, A.O., Omole, O.M. et Chianumba, E.C., (2024). Détection de fraude alimentée par l’IA dans le secteur bancaire : une revue systématique des approches de science des données pour améliorer la cybersécurité. GSC Advanced Research and Reviews, 21 (2), pp.227–237. https://gsconlinepress.com/journals/gscarr/sites/default/files/GSCARR-2024-0418.pdf
Patil, D., (2024). Intelligence artificielle dans les services financiers : gestion des risques et détection de la fraude. SSRN Electronic Journal. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5057412
Cette histoire a été publiée à l’origine le 14 août 2024.
Recevez de nouveaux articles dans votre boîte de réception.
Aucun spam. Désabonnez-vous à tout moment.