Tecnologia · 4 min read · Oct 10, 2025
Sobre a personalização do ‘Hey Siri’ explica no Machine Learning Journal
Em uma nova postagem no Machine Learning Journal da Apple, a empresa explica como a personalização funciona por trás do recurso de ativação por voz “Hey Siri” para reduzir o número de falsos positivos. O jornal remete a uma entrada anterior que descreve a abordagem técnica geral e os detalhes de implementação do detector “Hey Siri” e do problema mais geral de “detecção de frases-chave” independente do falante, e começa com isso como uma base assumida para este último artigo, que se concentra nas tecnologias de aprendizado de máquina que a Apple implementou no desenvolvimento de um sistema rudimentar de reconhecimento de falante para reduzir o número de falsos positivos acionados por outras pessoas nas proximidades dizendo frases que podem soar semelhantes a “Hey Siri.”
A Apple introduziu o “Hey Siri” com a estreia do iPhone 6 em 2014, embora o recurso originalmente exigisse que o iPhone estivesse conectado a uma fonte de energia; foi apenas com a estreia do iPhone 6s um ano depois que o “Hey Siri sempre ativo” se tornou disponível, graças a um novo coprocessador de baixo consumo que poderia oferecer escuta contínua sem um consumo significativo da bateria. Ao mesmo tempo, o recurso também foi ainda mais aprimorado no iOS 9, adicionando um novo “modo de treinamento” para ajudar a personalizar a Siri para a voz do usuário específico do iPhone durante a configuração inicial.
O artigo prossegue explicando que a frase “Hey Siri” foi originalmente escolhida para ser o mais natural possível, acrescentando que mesmo antes da introdução do recurso, a Apple descobriu que muitos usuários estavam naturalmente começando seus pedidos à Siri com “Hey Siri” após usar o botão home para ativá-la. No entanto, a “brevidade e facilidade de articulação” da frase é uma espada de dois gumes, uma vez que também tem o potencial de resultar em muitos mais falsos positivos; como a Apple explica, experimentos iniciais mostraram um número inaceitavelmente alto de ativações não intencionais que eram desproporcionais à “taxa razoável” de invocações corretas.
O objetivo da Apple, portanto, tem sido aproveitar as tecnologias de aprendizado de máquina para reduzir o número de “Falsos Aceites” para garantir que a Siri só acorde quando o usuário principal disser “Hey Siri,” e evitar particularmente situações em que uma terceira parte na sala diga algo que seja mal interpretado como um chamado para a Siri.
A Apple acrescenta que “o objetivo geral” da tecnologia de reconhecimento de falante é determinar a identidade de uma pessoa pela voz, sugerindo planos de longo prazo que podem oferecer personalização adicional e até autenticação, particularmente à luz de dispositivos de múltiplos usuários, como o HomePod da Apple. O objetivo é determinar “quem está falando” em vez de simplesmente o que está sendo dito, e o artigo prossegue explicando a diferença entre “reconhecimento de falante dependente de texto” onde a identificação é baseada em uma frase conhecida (como “Hey Siri”), e a tarefa mais desafiadora de reconhecimento de falante “independente de texto” que envolve identificar um usuário independentemente do que ele está dizendo.
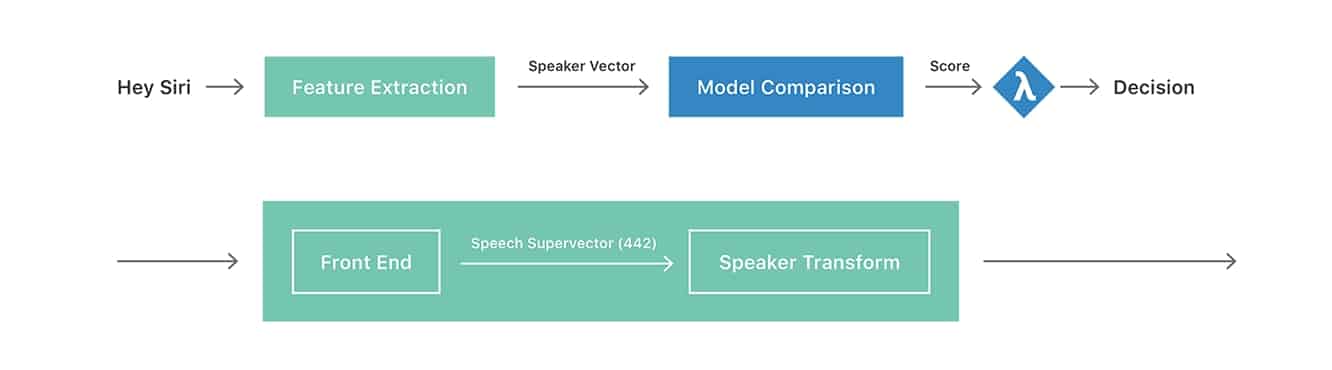
Talvez o mais interessante, o jornal explica como a Siri continua a “implicitamente” treinar-se para identificar a voz de um usuário, mesmo após o processo de inscrição explícito (pedindo ao usuário para dizer cinco frases diferentes de “Hey Siri” durante a configuração inicial) ter sido concluído. O processo implícito continua a treinar a Siri após a configuração inicial, analisando pedidos adicionais de “Hey Siri” e adicionando-os ao perfil do usuário até que um total de 40 amostras (conhecidas como “vetores de falante”) tenham sido armazenadas, incluindo os cinco originais do processo de treinamento explícito.
Essa coleção de vetores de falante é então usada para comparar com futuros pedidos de “Hey Siri” para determinar sua validade. A Apple também observa que a parte “Hey Siri” de cada forma de onda de enunciação também é armazenada localmente no iPhone para que os perfis de usuário possam ser reconstruídos usando essas formas de onda armazenadas sempre que transformações aprimoradas forem incorporadas nas atualizações do iOS. O artigo também postula um futuro onde nenhum passo de inscrição explícito será necessário, e os usuários poderão começar a usar o recurso “Hey Siri” a partir de um perfil vazio que crescerá e se atualizará organicamente. No momento, no entanto, parece que o treinamento explícito é necessário para fornecer uma linha de base para garantir a precisão do treinamento implícito posterior.
Embora não seja surpreendente, considerando a posição da Apple sobre privacidade, ainda vale a pena notar que toda essa computação e o armazenamento do perfil de voz do usuário ocorrem exclusivamente no iPhone de cada usuário, em vez de em qualquer um dos servidores da Apple, sugerindo que tais perfis não estão atualmente sincronizados entre dispositivos de forma alguma.
Receba novas postagens na sua caixa de entrada
Sem spam. Cancele a assinatura a qualquer momento.