Fraude de Suscripción · 12 min read · Feb 09, 2026
Del abuso de pruebas gratuitas a la acumulación de promociones: Cómo la IA está liderando la lucha contra el fraude de suscripción

El fraude de suscripción no actúa como el fraude—por eso la mayoría de los sistemas no lo detectan. Ya no son tarjetas bloqueadas o picos en ventas flash—son pruebas gratuitas fantasma, acumulación de promociones y suplantación de dispositivos coordinada que imitan el comportamiento real del usuario.
Soy Divesh Singh Sai, un Ingeniero de Software Senior con más de una década de experiencia construyendo sistemas de prevención de fraude para plataformas de pago digital de alta escala—donde cada milisegundo cuenta y cada transacción podría ser un riesgo.
En este artículo, explicaré cómo construimos defensas adaptativas contra el fraude para pagos de suscripción utilizando aprendizaje supervisado, detección de anomalías y modelado de comportamiento.
Si estás construyendo sistemas de fraude a gran escala—o tratando de entender cómo la IA descubre amenazas ocultas a simple vista—esta guía te dará los patrones técnicos y estrategias que funcionan en producción.
Cómo mi trabajo generó un enfoque en el fraude de suscripción
Mi interés en la detección de fraude impulsada por IA no comenzó en teoría—comenzó en producción.
Mientras trabajaba en servicios de pago, asumí el desafío de mejorar la capacidad de la plataforma para detectar comportamientos de pago inusuales.
El proyecto comenzó con sistemas basados en reglas, donde marcábamos transacciones utilizando condiciones predefinidas: múltiples pagos fallidos, ubicaciones de dispositivos inusuales o cambios rápidos de cuenta.
Sin embargo, a medida que el servicio se expandió globalmente y los defraudadores se volvieron más sofisticados, esas reglas estáticas se convirtieron en pasivos.
Un ejemplo destacado es cuando notamos un aumento en el uso indebido de pruebas gratuitas. Los usuarios crearon múltiples cuentas en diferentes dispositivos y regiones, explotando códigos promocionales y brechas de precios regionales.
Debido a que estas acciones no violaban ninguna regla individual, se deslizaron entre las grietas. Ahí fue cuando vimos cuán rápidamente las reglas se convirtieron en pasivos.
En respuesta, ayudé a liderar iniciativas que utilizaron IA y ML para captar patrones más matizados. Implementamos capas de detección de fraude capaces de rastrear el comportamiento a través de cuentas y dispositivos, identificando anomalías que no eran obvias a nivel de transacción individual.
Esta transformación, que abarcó plataformas de navegador, TV y móviles, me impulsó a explorar técnicas de ML de vanguardia—especialmente aquellas que podían operar en tiempo real y manejar grandes volúmenes de datos.
Por qué los sistemas tradicionales no son suficientes en la detección de fraude de suscripción
Los desarrolladores diseñaron originalmente métodos convencionales de detección de fraude—como motores de reglas estáticas, modelos estadísticos y listas de bloqueo—para casos de uso más sencillos.
Estos métodos funcionan bien cuando los patrones son predecibles, como detectar un aumento repentino en el volumen de transacciones o una dirección IP sospechosa.
Sin embargo, los servicios de suscripción introducen relaciones continuas entre usuarios y plataformas, lo que significa que el comportamiento fraudulento a menudo se extiende en el tiempo y se disfraza como actividad regular.
Por ejemplo, un defraudador podría usar una tarjeta robada para iniciar una suscripción, consumir contenido e iniciar un contracargo un mes después.
O podrían tomar el control de una cuenta legítima, cambiar el método de pago y agregar silenciosamente varias suscripciones adicionales. Los sistemas basados en reglas a menudo pasan por alto estos ataques lentos porque dependen de señales de alerta inmediatas en lugar de tendencias de comportamiento.
Experimenté esto de primera mano mientras trabajaba en sistemas de prevención de fraude. Tuvimos casos donde actores maliciosos manipularon renovaciones de suscripción, ventanas de prueba y límites de dispositivos de maneras que no eran detectables solo con reglas.
Estos fracasos frustraron a los usuarios y erosionaron la confianza del cliente, a menudo desencadenando intervenciones de soporte innecesarias.
Esta no fue solo nuestra experiencia. Un artículo de SSRN sobre inteligencia artificial en servicios financieros destaca la incapacidad de los sistemas estáticos para adaptarse a las técnicas de fraude en evolución. Estos hallazgos se alinean fuertemente con lo que observé en la práctica.
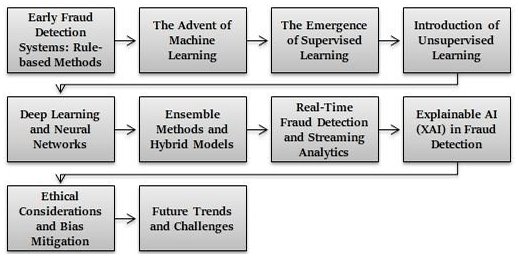
Cómo usamos IA para atrapar fraudes que nunca verás venir

“Mucho de lo que hacemos con el aprendizaje automático sucede bajo la superficie. El aprendizaje automático impulsa nuestros algoritmos para pronóstico de demanda, clasificación de búsqueda de productos, recomendaciones de productos y ofertas, colocaciones de merchandising, detección de fraude, traducciones y mucho más.” — Jeff Bezos, a través de Four.co.uk
Esta cita refleja lo que vi de primera mano en mi trabajo. Los sistemas de aprendizaje automático más efectivos a menudo operan silenciosamente en segundo plano—pero son críticos, especialmente en la detección de fraude.
En los sistemas de pago por suscripción, vimos que ningún algoritmo único podía resolver las complejidades del fraude de suscripción. Pasamos de sistemas estáticos basados en reglas a enfoques en capas impulsados por ML, cada uno abordando un patrón de fraude diferente.
Esto nos permitió detectar anomalías basadas en el comportamiento en tiempo real en lugar de depender de desencadenantes de reglas predecibles.
Aprendizaje Supervisado para la Detección de Fraude
El aprendizaje supervisado desempeñó un papel fundamental en nuestra canalización de fraude. Utilizamos algoritmos como Árboles de Decisión, Bosques Aleatorios y Máquinas de Aumento de Gradiente para clasificar transacciones basadas en patrones de fraude conocidos.
Entrenamos estos modelos con datos etiquetados—casos que ya habíamos identificado como fraudulentos o legítimos—y los usamos para detectar comportamientos repetidos como la acumulación de suscripciones y la prueba de métodos de pago mucho antes de que la revisión humana pudiera hacerlo.
Un estudio de GSCARR respalda este enfoque, mostrando que los modelos supervisados reducen significativamente los falsos positivos y mejoran la precisión de la detección de fraude en plataformas de alto volumen como la banca digital y los servicios de streaming.
Aprendizaje No Supervisado para la Detección de Anomalías
Algunos fraudes no se repiten. Se mutan.
Nos dirigimos al aprendizaje no supervisado, utilizando métodos como Autoencoders, Agrupamiento K-Means y Bosques de Aislamiento para identificar anomalías sin requerir datos etiquetados.
Estos modelos ayudaron a descubrir amenazas emergentes, como el abuso coordinado de promociones—al detectar valores atípicos en el comportamiento, como inscripciones repetidas a pruebas desde IDs de dispositivos ligeramente alterados.
Un artículo de investigación publicado por ESP-IJACT mostró que estos modelos no supervisados redujeron la revisión manual de fraude al captar señales de fraude previamente no vistas que los sistemas convencionales a menudo pasan por alto.
Detección en Tiempo Real con Aprendizaje Profundo
El aprendizaje profundo fue esencial para manejar comportamientos complejos y secuenciados en tiempo real. Utilizamos Redes Neuronales Recurrentes (RNN) y Redes Neuronales Convolucionales (CNN) para monitorear acciones de usuarios a lo largo del tiempo, rastreando cómo los usuarios navegaban, se suscribían, cambiaban de dispositivos o iniciaban sesión desde nuevas regiones.
Estos modelos procesaron los viajes de los usuarios—inicio de sesión, navegación, suscripción, cambio de dispositivos, cancelación—y marcaron cualquier cosa que rompiera el flujo esperado.
Según IJFMR, los modelos de aprendizaje profundo pueden ofrecer velocidades de inferencia de menos de 50 ms en producción, permitiendo la detección de fraude sin introducir latencia en la experiencia del usuario. Este rendimiento coincidió con nuestra experiencia al implementar modelos a través de AWS Lambda para inferencia en tiempo real.
Análisis de Comportamiento y Perfilado de Usuarios
Otra capa clave de detección provino del análisis de comportamiento. Utilizamos Modelos Ocultos de Markov (HMM) y redes de Memoria a Largo y Corto Plazo (LSTM) para perfilar el comportamiento del usuario a lo largo del tiempo.
Perfilamos el comportamiento a través de patrones de inicio de sesión, hábitos de dispositivos y longitudes de sesión. Esto nos ayudó a detectar diferencias entre usuarios reales y defraudadores, especialmente aquellos que se esconden detrás de VPN o emuladores.
El modelado de comportamiento fue especialmente crítico para proteger cuentas de usuarios a través de dispositivos y plataformas de streaming, donde la actividad fraudulenta a menudo reflejaba de cerca el comportamiento legítimo del usuario.
Detección de Fraude Basada en Gráficos
Para detectar fraude coordinado, introdujimos Redes Neuronales de Grafos (GNN). Estos modelos mapearon relaciones entre usuarios, dispositivos, direcciones IP y métodos de pago.
En un caso, descubrimos una red de fraude que explotaba códigos promocionales al vincular docenas de cuentas aparentemente no relacionadas que compartían huellas de pago e IDs de dispositivos.
Este enfoque basado en gráficos ayudó a revelar abusos organizados a gran escala, a menudo invisibles para los sistemas tradicionales basados en reglas. Se convirtió en una de las actualizaciones más impactantes en nuestra pila de detección, especialmente en un entorno de suscripción donde los actores maliciosos colaboran para eludir los límites de la plataforma.
Lo que se necesita para ejecutar la detección de fraude con IA a gran escala
Traducir modelos de IA de la teoría a la práctica fue una parte fundamental de mi trabajo en sistemas de pago por suscripción.
Más allá de seleccionar los modelos adecuados, necesitábamos asegurarnos de que nuestros sistemas pudieran operar a gran escala, manejar grandes volúmenes de datos y ofrecer información en tiempo real, sin interrumpir la experiencia del cliente.
Esto involucró todo, desde la ingeniería de características hasta el despliegue en la nube y la iteración constante basada en datos en vivo.
Recolección de Datos e Ingeniería de Características
Construimos nuestros modelos de fraude sobre datos de alta calidad. Recopilamos varios metadatos, como valor de transacción, marcas de tiempo, geolocalización IP, ID de dispositivo y comportamiento del usuario a través de sesiones y dispositivos. Para obtener información específica de suscripción, ingenierizamos características como:
Velocidad de transacción a través de ventanas cortas
Consistencia en el uso de dispositivos a través de cuentas
Duración del método de pago y comportamiento de cambio
Patrones del ciclo de vida de suscripción (por ejemplo, reactivaciones después de pruebas gratuitas)
Como parte de los estándares de ingeniería y cumplimiento de grado empresarial, también aseguramos que estos datos permanecieran anonimizados y cumplieran con las políticas de privacidad internas y regulaciones regionales.
Entrenamiento y Evaluación de Modelos
En mi papel liderando iniciativas de detección de fraude, traduje señales comerciales en características escalables listas para modelos para apoyar la detección de fraude.
Trabajamos con grandes volúmenes de datos de transacciones de producción enriquecidos por metadatos, capturando indicadores de comportamiento como consistencia de dispositivos, frecuencia de cambio de pago y uso de códigos promocionales.
Alineé nuestras señales con el abuso real de suscripciones, como reciclaje de pruebas y acumulación de promociones coordinadas. Estas ideas informaron los modelos que implementamos en nuestros sistemas de detección de pagos.
Aprovechar características contextuales del comportamiento del usuario, en lugar de depender únicamente de los valores de transacción, mejora significativamente el rendimiento de la detección de fraude basada en IA.
Después del despliegue, monitoreamos de cerca cómo funcionaban los modelos en entornos en vivo. Me enfoqué en asegurar que la canalización de fraude se alineara con los objetivos de experiencia del producto, adaptándose a medida que evolucionaban el comportamiento del usuario y los patrones de fraude. Esto nos ayudó a asegurar una fuerte cobertura contra el fraude mientras preservábamos una experiencia fluida para los usuarios legítimos.
Integración con Sistemas de Pago
La detección de fraude también tenía que funcionar en tiempo real. Desplegamos modelos en producción utilizando lo siguiente:
AWS Lambda, para inferencia rápida
DynamoDB, para almacenar y recuperar puntajes de riesgo
Microservicios y APIs para enrutar casos marcados
Kafka, para transmisión y escalado a través de regiones
Esta arquitectura aseguró que nuestro sistema pudiera marcar amenazas antes de que se completara la transacción, mientras permanecía invisible para todos menos para el defraudador.

Aprendizaje y Adaptación Continua
Los defraudadores evolucionan, y nuestros sistemas también deben hacerlo. Implementamos bucles de retroalimentación que ingerían casos de fraude confirmados por analistas y ajustaban el comportamiento del modelo en consecuencia.
En proyectos selectos, también exploramos enfoques de aprendizaje por refuerzo que optimizaban no solo la tasa de detección de fraude, sino también la minimización de falsos positivos a largo plazo.
Tendencias Futuras en la Prevención de Fraude Impulsada por IA

Las innovaciones que priorizan la transparencia, la colaboración y la integridad de los datos están dando forma al futuro de la detección de fraude mientras mantienen la velocidad y la escala demandadas por las plataformas de suscripción.
IA Explicable (XAI)
La parte más difícil de la IA no es construirla. Es explicar por qué tomó una decisión.
Los interesados—desde oficiales de cumplimiento hasta equipos de servicio al cliente—deben entender por qué se marcó una transacción. La IA explicable nos permite proporcionar el razonamiento detrás de cada decisión de fraude.
Según Science Times (2024), la demanda de modelos de IA transparentes está acelerándose, con instituciones que buscan herramientas que apoyen el cumplimiento regulatorio y la confianza del cliente.
Aprendizaje Federado
En organizaciones globales, los datos a menudo están aislados o gobernados por leyes de privacidad regionales. El aprendizaje federado aborda esto entrenando modelos a través de fuentes de datos distribuidas sin mover los datos. Hace posible la defensa colaborativa contra el fraude mientras se protege la privacidad del usuario.
Es un modelo que hemos comenzado a explorar dentro de sistemas a gran escala para fortalecer las señales de fraude a través de servicios, sin exponer o centralizar datos sensibles de usuarios.
Prevención de Fraude Basada en Blockchain
Aunque aún está emergiendo, la blockchain ofrece un potencial convincente para asegurar la integridad de las transacciones. Utilizar libros de contabilidad descentralizados asegura que cada transacción sea verificable, a prueba de manipulaciones y rastreable—vital para prevenir el fraude de suscripción basado en identidad y el robo de activos digitales.
Hacia Dónde Va el Fraude de Suscripción a Continuación (Y Cómo Prepararse)
El fraude en pagos digitales basados en suscripción está creciendo y volviéndose más sofisticado. Desde el abuso de pruebas gratuitas hasta la ingeniería social, los defraudadores evolucionan rápidamente sus tácticas.
En mi trabajo liderando la detección de fraude para plataformas de pago por suscripción, vi de primera mano cómo los sistemas tradicionales no son suficientes y cómo la IA y el aprendizaje automático pueden transformar la detección.
Utilizando enfoques de aprendizaje supervisado y no supervisado, modelado de comportamiento y análisis de gráficos, construimos soluciones escalables que se adaptan en tiempo real.
Sin embargo, la prevención efectiva del fraude requiere más que solo herramientas innovadoras. Se necesita visión—visión para crear sistemas adaptativos y transparentes que protejan tanto a los clientes como a los resultados comerciales.
Si estás esperando para actuar, ya estás atrasado.
Referencias:
Adaboina, S.R., (2024). IA y ML en la Detección de Fraude: Cómo los Algoritmos Están Capturando Criminales. Science Times. https://www.sciencetimes.com/articles/60131/20241216/ai-ml-fraud-detection.htm
Chopra, P. y Binwal, A., (2024). Mejorando la Seguridad y la Detección de Fraude en Pagos Digitales Usando Aprendizaje Automático. International Journal for Multidisciplinary Research, 6(6). https://www.ijfmr.com/papers/2024/6/30337.pdf
Mahapatra, B.G., (2024). IA y Aprendizaje Automático en la Detección de Fraude. ESP International Journal of Advancements in Computational Technology, 2(4), pp.125–139. https://www.espjournals.org/IJACT/2024/Volume2-Issue4/IJACT-V2I4P117.pdf
Olowu, O., Adeleye, A.O., Omokanye, A.O., Ajayi, A.M., Adepoju, A.O., Omole, O.M. y Chianumba, E.C., (2024). Detección de fraude impulsada por IA en la banca: Una revisión sistemática de enfoques de ciencia de datos para mejorar la ciberseguridad. GSC Advanced Research and Reviews, 21 (2), pp.227–237. https://gsconlinepress.com/journals/gscarr/sites/default/files/GSCARR-2024-0418.pdf
Patil, D., (2024). Inteligencia Artificial en Servicios Financieros: Gestión de Riesgos y Detección de Fraude. SSRN Electronic Journal. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5057412
Esta historia fue publicada originalmente el 14 de agosto de 2024.
Recibe nuevas publicaciones en tu bandeja de entrada.
No spam. Cancela la suscripción en cualquier momento.