Tecnologia · 3 min read · Oct 10, 2025
Apple spiega la personalizzazione di ‘Hey Siri’ nel Machine Learning Journal
In un nuovo post nel Machine Learning Journal di Apple, l’azienda spiega come funziona la personalizzazione dietro la funzione di attivazione vocale “Hey Siri” per ridurre il numero di falsi positivi. Il journal fa riferimento a un precedente articolo che descrive l’approccio tecnico generale e i dettagli di implementazione del rilevatore “Hey Siri” e del problema più generale della “rilevazione di frasi chiave” indipendente dall’oratore, e inizia con questo come base assunta per questo ultimo documento, che si concentra sulle tecnologie di machine learning che Apple ha implementato nello sviluppo di un sistema rudimentale di riconoscimento dell’oratore per ridurre il numero di falsi positivi attivati da altre persone nelle vicinanze che dicono frasi che possono suonare simili a “Hey Siri.”
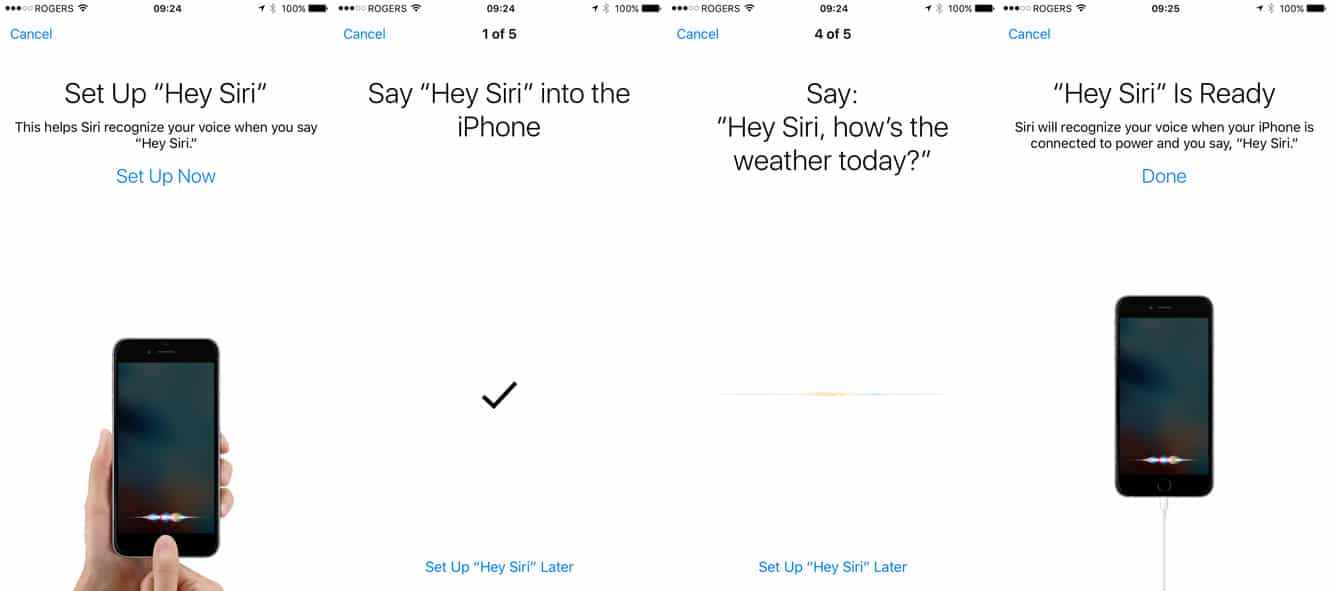
Apple ha introdotto “Hey Siri” con il debutto dell’iPhone 6 nel 2014, anche se la funzione richiedeva inizialmente che l’iPhone fosse collegato a una fonte di alimentazione; è stato solo con il debutto dell’iPhone 6s un anno dopo che “Hey Siri sempre attivo” è diventato disponibile, grazie a un nuovo coprocessore a bassa potenza che poteva offrire ascolto continuo senza un significativo consumo della batteria. Allo stesso tempo, la funzione è stata ulteriormente migliorata in iOS 9 aggiungendo una nuova “modalità di addestramento” per aiutare a personalizzare Siri alla voce dell’utente specifico dell’iPhone durante la configurazione iniziale.
Il documento prosegue spiegando che la frase “Hey Siri” è stata originariamente scelta per essere il più naturale possibile, aggiungendo che anche prima dell’introduzione della funzione, Apple ha scoperto che molti utenti iniziavano naturalmente le loro richieste a Siri con “Hey Siri” dopo aver utilizzato il pulsante home per attivarla. Tuttavia, la “brevità e facilità di articolazione” della frase è una lama a doppio taglio, poiché ha anche il potenziale di generare molti più falsi positivi; come spiega Apple, i primi esperimenti hanno mostrato un numero inaccettabilmente alto di attivazioni non intenzionali che erano sproporzionate rispetto al “tasso ragionevole” di invocazioni corrette.
L’obiettivo di Apple è quindi stato quello di sfruttare le tecnologie di machine learning per ridurre il numero di “Falsi Accettazioni” per garantire che Siri si attivi solo quando l’utente principale dice “Hey Siri,” e per evitare in particolare situazioni in cui una terza parte nella stanza dice qualcosa che viene frainteso come una chiamata per Siri.
Apple aggiunge che “l’obiettivo generale” della tecnologia di riconoscimento dell’oratore è determinare l’identità di una persona tramite la voce, suggerendo piani a lungo termine che potrebbero offrire ulteriore personalizzazione e persino autenticazione, in particolare alla luce di dispositivi multi-utente come l’HomePod di Apple. L’obiettivo è determinare “chi sta parlando” piuttosto che semplicemente cosa viene detto, e il documento prosegue spiegando la differenza tra “riconoscimento dell’oratore dipendente dal testo” dove l’identificazione si basa su una frase nota (come “Hey Siri”), e il compito più impegnativo del riconoscimento dell’oratore “indipendente dal testo” che implica identificare un utente indipendentemente da ciò che stanno dicendo.
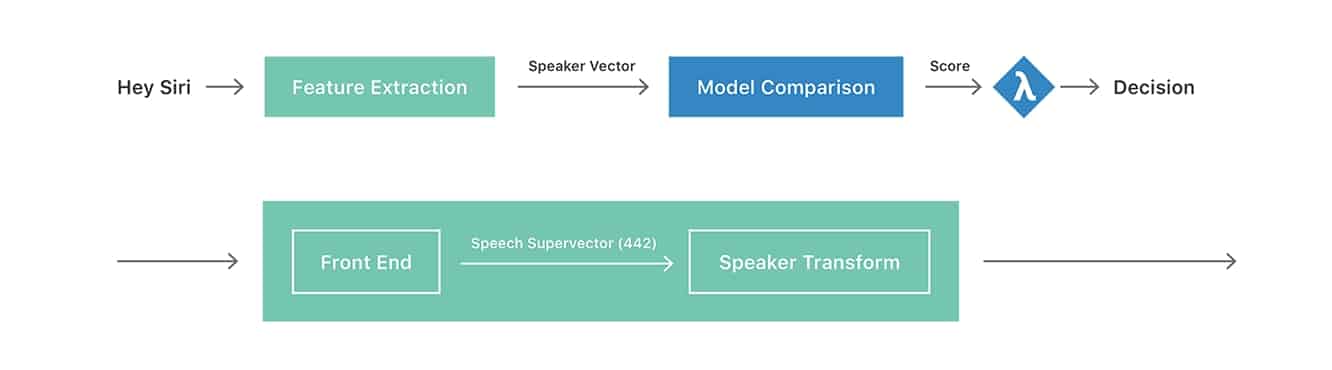
Forse la cosa più interessante è che il journal spiega come Siri continui a “formarsi implicitamente” per identificare la voce di un utente, anche dopo che il processo di registrazione esplicita (chiedendo all’utente di dire cinque diverse frasi “Hey Siri” durante la configurazione iniziale) è stato completato. Il processo implicito continua a formare Siri dopo la configurazione iniziale analizzando ulteriori richieste “Hey Siri” e aggiungendole al profilo dell’utente fino a quando un totale di 40 campioni (noti come “vettori dell’oratore”) sono stati memorizzati, inclusi i cinque originali dal processo di addestramento esplicito.
Questa raccolta di vettori dell’oratore viene quindi utilizzata per confrontare le future richieste “Hey Siri” per determinarne la validità. Apple nota anche che la parte “Hey Siri” di ogni forma d’onda dell’utterance è memorizzata localmente sull’iPhone in modo che i profili utente possano essere ricostruiti utilizzando quelle forme d’onda memorizzate ogni volta che vengono incorporate trasformazioni migliorate negli aggiornamenti di iOS. Il documento ipotizza anche un futuro in cui non sarà necessario alcun passaggio di registrazione esplicita, e gli utenti potranno semplicemente iniziare a utilizzare la funzione “Hey Siri” da un profilo vuoto che crescerà e si aggiornerà organicamente. Al momento, tuttavia, sembra che l’addestramento esplicito sia necessario per fornire una base per garantire l’accuratezza del successivo addestramento implicito.
Sebbene non sorprendente considerando la posizione di Apple sulla privacy, vale comunque la pena notare che tutto questo calcolo e la memorizzazione del profilo vocale dell’utente avviene esclusivamente su ciascun iPhone dell’utente, piuttosto che su uno dei server di Apple, suggerendo che tali profili non sono attualmente sincronizzati tra i dispositivi in alcun modo.
Ricevi i nuovi post nella tua casella di posta.
Nessuno spam. Disiscriviti in qualsiasi momento.