Мошенничество · 10 min read · Feb 09, 2026
От злоупотребления бесплатными пробными версиями до накопления промо-кодов: как ИИ ведет борьбу с мошенничеством в подписках

Мошенничество с подписками не ведет себя как мошенничество — именно поэтому большинство систем не замечает его. Это больше не флажки по картам или всплески распродаж — это призрачные бесплатные пробные версии, накопление промо-кодов и координированное подделывание устройств, которые имитируют поведение реальных пользователей.
Я — Дивеш Сингх Сай, старший инженер-программист с более чем десятилетним опытом создания систем предотвращения мошенничества для высокомасштабных цифровых платежных платформ, где каждая миллисекунда имеет значение, а каждая транзакция может быть риском.
В этой статье я объясню, как мы построили адаптивные защиты от мошенничества для подписочных платежей, используя контролируемое обучение, обнаружение аномалий и поведенческое моделирование.
Если вы создаете системы предотвращения мошенничества в большом масштабе или пытаетесь понять, как ИИ выявляет угрозы, скрытые на виду, этот гид даст вам технические шаблоны и стратегии, которые работают в производстве.
Как моя работа привлекла внимание к мошенничеству с подписками
Мой интерес к обнаружению мошенничества с помощью ИИ не начался с теории — он начался с практики.
Работая над платежными сервисами, я взял на себя задачу улучшить способность платформы обнаруживать необычное поведение при оплате.
Проект начался с систем на основе правил, где мы отмечали транзакции, используя заранее определенные условия: множественные неудачные платежи, необычные местоположения устройств или быстрое переключение аккаунтов.
Однако, по мере того как сервис масштабировался глобально и мошенники становились более изощренными, эти статические правила стали обременительными.
Одним из ярких примеров является тот случай, когда мы заметили всплеск злоупотребления бесплатными пробными версиями. Пользователи создавали несколько аккаунтов на разных устройствах и в разных регионах, используя промо-коды и региональные ценовые разрывы.
Поскольку эти действия не нарушали ни одно отдельное правило, они ускользнули от внимания. Именно тогда мы увидели, как быстро правила становятся обременительными.
В ответ я помог возглавить инициативы, которые использовали ИИ и машинное обучение для выявления более тонких паттернов. Мы внедрили уровни проверки мошенничества, способные отслеживать поведение по аккаунтам и устройствам, выявляя аномалии, которые не были очевидны на уровне отдельных транзакций.
Эта трансформация, охватывающая браузеры, телевизоры и мобильные платформы, подтолкнула меня к изучению передовых методов машинного обучения — особенно тех, которые могли бы работать в реальном времени и обрабатывать огромные объемы данных.
Почему традиционные системы не справляются с обнаружением мошенничества в подписках
Разработчики изначально создавали традиционные методы обнаружения мошенничества — такие как статические движки правил, статистические модели и черные списки — для более простых случаев использования.
Эти методы хорошо работают, когда паттерны предсказуемы, например, при обнаружении резкого всплеска объема транзакций или подозрительного IP-адреса.
Однако подписочные сервисы вводят постоянные отношения между пользователями и платформами, что означает, что мошенническое поведение часто растягивается во времени и маскируется под обычную активность.
Например, мошенник может использовать украденную карту, чтобы начать подписку, потреблять контент и инициировать возврат через месяц.
Или он может захватить легитимный аккаунт, изменить способ оплаты и тихо добавить несколько дополнительных подписок. Системы на основе правил часто пропускают эти медленные атаки, потому что они полагаются на немедленные тревожные сигналы, а не на поведенческие тенденции.
Я столкнулся с этим на собственном опыте, работая над системами предотвращения мошенничества. У нас были случаи, когда злоумышленники манипулировали продлением подписок, окнами пробных версий и лимитами устройств таким образом, что их нельзя было обнаружить только с помощью правил.
Эти неудачи разочаровывали пользователей и подрывали доверие клиентов, часто вызывая ненужные вмешательства поддержки.
Это была не только наша проблема. Статья SSRN о искусственном интеллекте в финансовых услугах подчеркивает неспособность статических систем адаптироваться к развивающимся мошенническим методам. Эти выводы сильно совпадают с тем, что я наблюдал на практике.
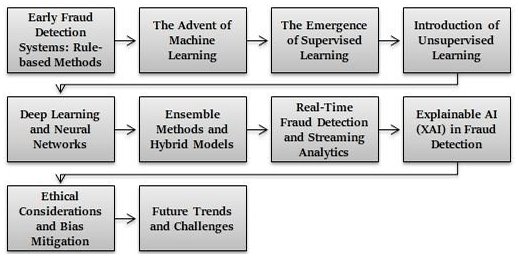
Как мы используем ИИ для выявления мошенничества, которое вы никогда не увидите

“Большая часть того, что мы делаем с машинным обучением, происходит под поверхностью. Машинное обучение управляет нашими алгоритмами для прогнозирования спроса, ранжирования поиска продуктов, рекомендаций продуктов и сделок, размещения мерчандайзинга, обнаружения мошенничества, переводов и многого другого.” — Джефф Безос, через Four.co.uk
Эта цитата отражает то, что я увидел на собственном опыте в своей работе. Наиболее эффективные системы машинного обучения часто работают тихо в фоновом режиме — но они критически важны, особенно в обнаружении мошенничества.
В системах подписочных платежей мы увидели, что ни один отдельный алгоритм не может решить сложности мошенничества с подписками. Мы перешли от статических систем на основе правил к многослойным подходам, управляемым машинным обучением, каждый из которых решает разные мошеннические паттерны.
Это позволило нам обнаруживать аномалии на основе поведения в реальном времени, а не полагаться на предсказуемые триггеры правил.
Контролируемое обучение для обнаружения мошенничества
Контролируемое обучение сыграло основополагающую роль в нашем процессе обнаружения мошенничества. Мы использовали алгоритмы, такие как деревья решений, случайные леса и градиентные бустинговые машины, чтобы классифицировать транзакции на основе известных мошеннических паттернов.
Мы обучали эти модели на размеченных данных — случаях, которые мы уже идентифицировали как мошеннические или легитимные — и использовали их для выявления повторяющегося поведения, такого как накопление подписок и тестирование способов оплаты задолго до того, как это могло быть рассмотрено человеком.
Исследование GSCARR поддерживает этот подход, показывая, что контролируемые модели значительно снижают количество ложных срабатываний и улучшают точность обнаружения мошенничества на платформах с высоким объемом, таких как цифровые банки и стриминговые сервисы.
Неконтролируемое обучение для обнаружения аномалий
Некоторое мошенничество не повторяется. Оно мутирует.
Мы обратились к неконтролируемому обучению, используя методы, такие как автоэнкодеры, кластеризация K-средних и изолирующие леса, чтобы выявлять аномалии без необходимости в размеченных данных.
Эти модели помогли выявить возникающие угрозы, такие как координированное злоупотребление промо-кодами, обнаруживая выбросы в поведении, такие как повторные регистрации на пробные версии с немного измененными идентификаторами устройств.
Научная статья, опубликованная ESP-IJACT, показала, что эти неконтролируемые модели сократили ручной обзор мошенничества, выявляя ранее невидимые сигналы мошенничества, которые традиционные системы часто пропускают.
Обнаружение в реальном времени с помощью глубокого обучения
Глубокое обучение было необходимо для обработки сложного, последовательного поведения в реальном времени. Мы использовали рекуррентные нейронные сети (RNN) и свёрточные нейронные сети (CNN) для мониторинга действий пользователей с течением времени, отслеживая, как пользователи просматривали, подписывались, переключали устройства или входили из новых регионов.
Эти модели обрабатывали пользовательские пути — вход, просмотр, подписка, переключение устройств, отмена — и отмечали все, что нарушало ожидаемый поток.
Согласно IJFMR, модели глубокого обучения могут обеспечивать скорость вывода менее 50 мс в производстве, позволяя обнаруживать мошенничество без введения задержек в пользовательский опыт. Эта производительность соответствовала нашему опыту развертывания моделей через AWS Lambda для вывода в реальном времени.
Поведенческая аналитика и профилирование пользователей
Еще одним ключевым уровнем обнаружения стала поведенческая аналитика. Мы использовали скрытые модели Маркова (HMM) и сети долгосрочной и краткосрочной памяти (LSTM) для профилирования поведения пользователей с течением времени.
Мы профилировали поведение по паттернам входа, привычкам устройств и длине сессий. Это помогло нам выявить различия между реальными пользователями и мошенниками, особенно теми, кто скрывался за VPN или эмуляторами.
Поведенческое моделирование было особенно критично для защиты аккаунтов пользователей на стриминговых устройствах и платформах, где мошенническая активность часто близко имитировала легитимное поведение пользователей.
Обнаружение мошенничества на основе графов
Чтобы выявить координированное мошенничество, мы внедрили графовые нейронные сети (GNN). Эти модели отображали отношения между пользователями, устройствами, IP-адресами и способами оплаты.
В одном случае мы раскрыли мошенническое кольцо, использующее промо-коды, связав десятки, казалось бы, несвязанных аккаунтов, которые делили отпечатки платежей и идентификаторы устройств.
Этот графовый подход помог выявить крупномасштабные, организованные злоупотребления, часто невидимые для традиционных систем на основе правил. Это стало одним из самых значительных обновлений нашего стека обнаружения, особенно в среде подписок, где злоумышленники сотрудничают, чтобы обойти лимиты платформы.
Что нужно для работы систем обнаружения мошенничества на основе ИИ в большом масштабе
Перевод моделей ИИ из теории в практику был ключевой частью моей работы в системах подписочных платежей.
Помимо выбора правильных моделей, нам нужно было убедиться, что наши системы могут работать в большом масштабе, обрабатывать огромные объемы данных и предоставлять информацию в реальном времени, не прерывая клиентский опыт.
Это включало все, от инженерии функций до облачного развертывания и постоянной итерации на основе живых данных.
Сбор данных и инженерия функций
Мы строили наши модели мошенничества на высококачественных данных. Мы собирали различные метаданные, такие как значение транзакции, временные метки, геолокация IP, идентификатор устройства и поведение пользователя по сессиям и устройствам. Для получения специфической информации о подписках мы разрабатывали функции, такие как:
- Скорость транзакций за короткие промежутки времени
- Согласованность использования устройств по аккаунтам
- Срок службы и поведение переключения способов оплаты
- Паттерны жизненного цикла подписки (например, реактивации после бесплатных пробных версий)
В рамках стандартов инженерии и соблюдения норм для предприятий мы также обеспечили, чтобы эти данные оставались анонимными и соответствовали внутренним политикам конфиденциальности и региональным нормативам.
Обучение и оценка моделей
В моей роли руководителя инициатив по обнаружению мошенничества я переводил бизнес-сигналы в масштабируемые функции, готовые к моделированию, для поддержки обнаружения мошенничества.
Мы работали с большими объемами производственных данных транзакций, обогащенных метаданными, захватывающими поведенческие индикаторы, такие как согласованность устройств, частота переключения платежей и использование промо-кодов.
Я согласовывал наши сигналы с реальными злоупотреблениями подписками, такими как переработка пробных версий и координированное накопление промо-кодов. Эти идеи информировали модели, которые мы развернули в наших системах проверки платежей.
Использование контекстуальных функций из поведения пользователей, а не полагание исключительно на значения транзакций, значительно улучшает производительность обнаружения мошенничества на основе ИИ.
После развертывания мы внимательно следили за тем, как модели работают в реальных условиях. Я сосредоточился на том, чтобы обеспечить соответствие процесса мошенничества целям пользовательского опыта, адаптируясь по мере изменения поведения пользователей и паттернов мошенничества. Это помогло нам обеспечить надежное покрытие мошенничества, сохраняя при этом бесшовный опыт для легитимных пользователей.
Интеграция с платежными системами
Обнаружение мошенничества также должно было работать в реальном времени. Мы развернули модели в производстве, используя следующее:
- AWS Lambda, для быстрого вывода
- DynamoDB, для хранения и извлечения оценок риска
- Микросервисы и API для маршрутизации отмеченных случаев
- Kafka, для потоковой передачи и масштабирования по регионам
Эта архитектура обеспечила, чтобы наша система могла отмечать угрозы до завершения транзакции, оставаясь невидимой для всех, кроме мошенника.

Непрерывное обучение и адаптация
Мошенники эволюционируют, и наши системы тоже должны. Мы внедрили обратные связи, которые поглощали подтвержденные аналитиками случаи мошенничества и соответственно корректировали поведение модели.
В некоторых проектах мы также исследовали подходы к обучению с подкреплением, которые оптимизировали не только уровень выявления мошенничества, но и минимизацию долгосрочных ложных срабатываний.
Будущие тенденции в предотвращении мошенничества на основе ИИ

Инновации, придающие приоритет прозрачности, сотрудничеству и целостности данных, формируют будущее обнаружения мошенничества, сохраняя при этом скорость и масштаб, требуемые платформами подписок.
Объяснимый ИИ (XAI)
Самая сложная часть ИИ — это не его создание. Это объяснение, почему он принял то или иное решение.
Заинтересованные стороны — от сотрудников по соблюдению норм до команд обслуживания клиентов — должны понимать, почему транзакция была отмечена. Объяснимый ИИ позволяет нам предоставить обоснование каждого решения о мошенничестве.
Согласно Science Times (2024), спрос на прозрачные модели ИИ растет, и учреждения ищут инструменты, поддерживающие соблюдение норм и доверие клиентов.
Федеративное обучение
В глобальных организациях данные часто изолированы или регулируются региональными законами о конфиденциальности. Федеративное обучение решает эту проблему, обучая модели на распределенных источниках данных без перемещения данных. Это делает возможной совместную защиту от мошенничества, сохраняя при этом конфиденциальность пользователей.
Это модель, которую мы начали исследовать в рамках систем большого масштаба, чтобы укрепить сигналы мошенничества по услугам, не раскрывая и не централизуя чувствительные данные пользователей.
Предотвращение мошенничества на основе блокчейна
Хотя это еще только начинает развиваться, блокчейн предлагает убедительный потенциал для обеспечения целостности транзакций. Использование децентрализованных реестров гарантирует, что каждая транзакция является проверяемой, защищенной от подделки и отслеживаемой — это жизненно важно для предотвращения мошенничества, основанного на идентичности, и кражи цифровых активов.
Куда движется мошенничество с подписками дальше (и как подготовиться)
Мошенничество в цифровых платежах на основе подписок растет и становится все более изощренным. От злоупотребления бесплатными пробными версиями до социальной инженерии мошенники быстро развивают свои тактики.
В моей работе по руководству проверкой мошенничества для платформ подписочных платежей я на собственном опыте увидел, как традиционные системы не справляются и как ИИ и машинное обучение могут трансформировать обнаружение.
Используя контролируемые и неконтролируемые подходы к обучению, поведенческое моделирование и графовый анализ, мы построили масштабируемые решения, которые адаптируются в реальном времени.
Тем не менее, эффективное предотвращение мошенничества требует большего, чем просто инновационные инструменты. Это требует видения — видения создания адаптивных, прозрачных систем, которые защищают как клиентов, так и бизнес-результаты.
Если вы ждете, чтобы действовать, вы уже отстаете.
Ссылки:
- Adaboina, S.R., (2024). ИИ и МЛ в обнаружении мошенничества: как алгоритмы ловят преступников. Science Times. https://www.sciencetimes.com/articles/60131/20241216/ai-ml-fraud-detection.htm
- Chopra, P. и Binwal, A., (2024). Улучшение безопасности и обнаружения мошенничества в цифровых платежах с использованием машинного обучения. Международный журнал многопрофильных исследований, 6(6). https://www.ijfmr.com/papers/2024/6/30337.pdf
- Mahapatra, B.G., (2024). ИИ и машинное обучение в обнаружении мошенничества. ESP Международный журнал достижений в вычислительных технологиях, 2(4), стр. 125–139. https://www.espjournals.org/IJACT/2024/Volume2-Issue4/IJACT-V2I4P117.pdf
- Olowu, O., Adeleye, A.O., Omokanye, A.O., Ajayi, A.M., Adepoju, A.O., Omole, O.M. и Chianumba, E.C., (2024). Обнаружение мошенничества на основе ИИ в банковском деле: систематический обзор подходов науки о данных для повышения кибербезопасности. GSC Advanced Research and Reviews, 21 (2), стр. 227–237. https://gsconlinepress.com/journals/gscarr/sites/default/files/GSCARR-2024-0418.pdf
- Patil, D., (2024). Искусственный интеллект в финансовых услугах: управление рисками и обнаружение мошенничества. SSRN Электронный журнал. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5057412
Эта история была первоначально опубликована 14 августа 2024 года.
Get new posts in your inbox
No spam. Unsubscribe anytime.